How to read this:
- Start with §1 for the core argument.
- Use §2 and §3 as the reference map for the main terms and framework.
- Go to §6 and §7 for the operating method.
- Use §4–§5 and §8–§10 for lineage, adjacent disciplines, claim maturity, and future work.
§1. The Argument
For years, the work of getting brands cited in the right buying conversations has happened under several names: link building, SEO, content marketing.
Each names a real tactical discipline. None names (or enables) the strategic discipline that organizes them. That strategic discipline has been doing the work the whole time; it has not had a name.
The keyword era constrained what buyers could ask. Search interfaces required them to compress messy decisions into a few words, and content marketers spent two decades optimizing for those compressed signals: keyword research, topic clusters, ranking factors, intent classifications.
AI search has removed the compression requirement. Buyers now describe their situation in their own words: the constraints they face, the people they must convince, the stakes they carry—and ask an assistant to evaluate fit, surface tradeoffs, and recommend options for their specific decision context.
The query has expanded into the prompt. The keyword has expanded into the situation.
For the first time, a technology surface meets the practitioner from inside their prompted decision-context, attempting to mimic expertise-laden human guidance.
And it does something we should name precisely.
When a buyer opens with an assistant, the assistant assembles an answer from a handful of sources and hands back a framed set of options, authorities, and cautions—a choice architecture.
That shapes the decision before any vendor is in the room.
The sources it cites are that architecture.
The strategic question is therefore not "are we visible to AI?" in the abstract. It is: in the decision environment the assistant constructs for each role on the buying committee, where does the brand sit (a default, a considered option, or absent) and where can we intervene?
Several surface-oriented labels have emerged to name the work:
- Answer Engine Optimization
- Generative Engine Optimization
- AI Visibility
They describe what the work optimizes for (the AI surface) without naming what it is designing for (the practitioner's decision). They are tactical labels in the SEO lineage—useful for the work they name, but tied to a technology surface rather than to the human work being served.
The discipline behind this work requires a different name.
Its unit of design is the practitioner's decision—the actual buying decision, the actual evaluation, the case the practitioner must make to colleagues, family, friends, even themselves.
The surfaces (AI, search, social, publisher pages) are how that decision gets accessed, not what the discipline is for.
We propose to call this discipline Decision Architecture.
Its unit of design is the practitioner's decision. Its unit of work is the choice point.
A decision is a constellation of choice points distributed across a committee of stakeholders. And each stakeholder is a practitioner in their own right, carrying their own object of practice through their own transition.
Each choice point is a specific moment where one such practitioner weighs evidence and nudges the decision forward or holds it back.
The discipline maps that constellation before designing content, and orchestrates content and source-material to reduce friction across the full decision lifecycle—before, during, and long after the moment of choosing.
Three tiers carry the workflow:
- Audience Decision Context (who is deciding what)
- Choice-Point Content (the work product)
- Citation Optimization + Impact Tracking (deployment and measurement)
And the discipline now has an operational way to read a committee: three lenses — node, edge, and trajectory. Each one has its own diagnostic and its own build target.
Decision architecture positions next to Information Architecture as a sibling: distinct in protagonist (practitioner-mid-decision rather than user-navigating), in unit of design (the decision rather than the page), and in success criterion (decision-enablement rather than findability).
What follows is a working treatise on Decision Architecture: its core terms, framework, practice method, intellectual debts, and the applied client work through which the discipline took shape. It also names PARSE, the parent framework that grounds the discipline.
It positions Decision Architecture as a discipline name that survives the next surface change, because it is named for the practitioner work being served, not the technology surface of the moment.
§2. Core Terms
This lexicon defines the principal constructs used throughout the treatise.
Each entry pairs a working definition with its role in the discipline and an honest status tag (where a construct is still being validated).
The terms are designed to be portable: a Decision Architect should be able to share the start-set (marked ★ below) with a colleague or client and have the team speak coherently within an hour. The rest is the full apparatus, picked up as the work demands it.
The constructs nest in three levels and are read through three lenses, served by three tiers of workflow. §3 shows how these relate (and includes a table that fixes the four triads in place).
This section defines the pieces.
Discipline and foundations
| Term | Definition | Role / status |
|---|---|---|
| Decision Architecture ★ | The discipline of mapping a practitioner's choice points for a decision, then designing and orchestrating content to reduce friction before, during, and after the decision. Unit of design: the decision. Unit of work: the choice point. | Umbrella discipline name. |
| Choice architecture (borrowed) | Thaler & Sunstein's design of the environment around a single choice (defaults, ordering, friction, nudges). Decision Architecture works the level above it. | Lineage term; always attributed, never a synonym for Decision Architecture (see §4.1). |
| Audience Decision Context ★ | The foundation: who the practitioner is, what decision they are inside, what committee they answer to, what stakes, constraints, and practice-perspectives they hold. | Tier 1 — establishes who the work serves. |
| Decision Phases | The temporal structure within which a decision unfolds. Canonical three-stage Citation Labs model (2022): Purchase Decisioning → Resource Planning → Benefit Maximization. A finer six-step cut is used in the trajectory lens (§6); the two are mapped in §6. Function-holding, exposure, choice points, content, and measurement all distribute across phases. | Temporal layer; the axis of the trajectory lens. |
| Theatre of Practice | The relational, narrative, temporal, and ritual field an artifact lands in — not merely the setting. It is determinative, not advisory: the same fragment can be metabolizable in one theater and fail in another. Diagnosed on five dimensions (temporal alignment, feedback density, stake traceability, return concreteness, stake diffusion). Inherited from PARSE (Doc 1). | Context dimension of Audience Decision Context. |
| Practitioner-in-Action | The audience identity: a real person doing real work, in a cycle, with stakes and constraints. (A Citation Labs term, 2017; PARSE's parallel seed concept is "the practitioner" — a context-bound transformation agent. Not a canonical PARSE seed concept under this name.) | Foundational audience claim. |
| Domain of Practice | The community-of-practice context a practitioner operates within. (A Citation Labs term, 2011; not a named PARSE seed concept — PARSE's nearest construct is the Theater of Practice.) | Audience-defining context. |
The committee and its structure
| Term | Definition | Role / status |
|---|---|---|
| Decision Committee ★ | The collective of role-holders for a decision, considered as a unit exhibiting committee dynamics — consensus formation, Champion-transfer, Silent-Veto risk, stake distribution. Present in every decision, even when its functions consolidate into one mind. Read as a diagnostic over N practitioners, not as a unit served in its own right (§3.2). | Composite audience structure within Audience Decision Context. |
| Decision Functions | The six functions every decision requires: Use, Judgment, Authorization, Defense, Exposure, Transition. Substrate-independent. | Canonical decomposition; populates the nodes. |
| Role-Assignment Pattern | The substrate-specific distribution of the six functions across human role-holders (B2B SaaS, B2C, healthcare, civic each differ). | Operational distinction. |
| Committee-as-graph | The committee read as a graph: nodes (role-holders) joined by two distinct edge types — citation-overlap edges (shared cited ground) and decision-dependency / veto edges (who can stop whose decision). A diagnostic layer over a single-practitioner framework, not a collective unit (§3.2). | Structural model underneath the lenses. [Open · n=3] |
| Node ★ | One role-holder treated as a unit — but the role-holder is a practitioner in their own right: an identity, a schema, an arc, a finite metabolism, and their own (often nested) object of practice, plus the Decision Function(s) they hold, the choice points they own, and the citation footprint those choice points draw. "Node" is the graph-word for that practitioner; the level between Choice Point and Committee. The reading inherits PARSE's N-Practitioners frame (Doc 18 §8): every role is its own practitioner. | Level 2 of the nesting. [Open · n=3] |
| Choice Point ★ | A specific moment within a decision where one practitioner weighs evidence and nudges toward or away from completing the Transition — or levies a post-purchase veto. The atomic unit, and the place where the discipline's parent framework asks its question (§3, §4.8). Carries a readable Choice-Point Profile. | Level 1; target of Choice-Point Content. |
| Choice-Point Profile ★ | The readable schema for any choice point, led by the practitioner's actual question and tagged on the diagnostic side: function (which of the six), phase, valence, dominant cost dimension(s), veto character (formal or attritional; see Silent Veto), FLUQ load, and constraint-grounding (physics / regulation / resource / symbolic). The instrument that makes a choice point recognizable rather than abstract. | Compositional read of a Choice Point. [Open · new] |
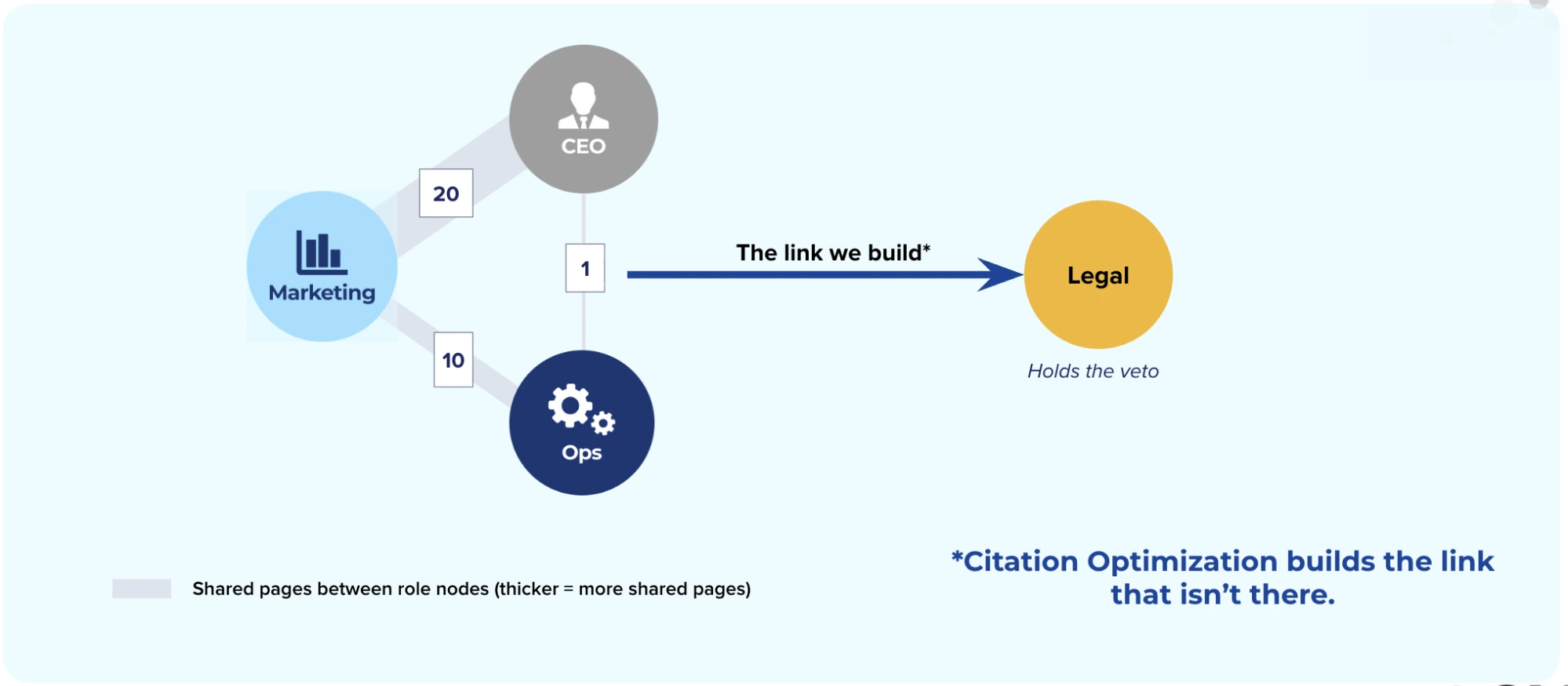
| Champion | The role-holder who assumes the Transition function — the internal initiator who stakes their reputation on the offering and carries the case across the other functions. In framework terms, the practitioner whose object of practice is the decision-as-a-whole — which is how the collective stays real inside a single-practitioner discipline (§3.2). Can transfer across committee members as the decision moves through phases. (Citation Labs, Nov 2023; debt to Bonoma 1982.) | Functional role within the committee. |
| Silent Veto ★ | A committee member's behavioral refusal to engage — expressed through non-action rather than objection. The discipline's name for what PARSE calls the continuous / attritional subtype of phase-distributed veto (Doc 13): a veto that fires by accumulated non-commitment rather than a decision-table "no." Often produced by role-to-role FUQs; its empirical fingerprint is the Isolate (§7). Distinct from explicit Veto (a formal objection during Purchase Decisioning — the formal / decision-table subtype). | Failure mode; key risk for the Transition-holder. | Charge ★ | A cost created at one seat's choice point and paid by another seat, later: in committing, a practitioner debits another role's stake balance. The committee-graph's flow-layer unit — directional, time-stamped, posted along a dependency edge and settled downstream (read via the settlement instrument, §6). Closure-gap's committee-plane sibling (PARSE Doc 9, Claim 21): the same transfer of unacknowledged cost, on the practitioner→practitioner plane rather than artifact→reader. Scored on two structural axes — legibility (was the charged stake visible at the originating choice point?) and declaration (posted openly, or silently?) — never on intent: from outside, malice and misestimation are indistinguishable, and misestimation of another seat's stake-weight is the design-tractable reading. Legibility itself splits: existence-legibility (knowing the stake is there — cheap, informational) and weight-legibility (its finality, substrate, and failure-cost — experiential, ordinarily acquired only by paying the gate once). Charges originate by sequencing, selection, omission, standing assignment, or conscription (§3.2), and the intervention differs by origin. The flow carries credits as well as debits: declaration does not merely avoid the silent debit, it posts a credit to both accounts — though settlement can be asymmetric: the work charged to one account while the credit posts to another (credit misallocation). And a charge does more than debit stake: it inserts an unscheduled choice point into the charged practitioner's trajectory — the settlement choice point (accept / contest / attritional veto), profilable like any other; conscription is the limit case, inserting an entire trajectory, and the felt friction is the misrecognition spike at the unscheduled node. Charges are denominated in the cost taxonomy's currencies — the chart of chargeable accounts (§6). The charge is not the failure; the undeclared charge is. | Flow-layer unit; the level between Choice Point and Committee. [Open · n=0 — theory frontier] | Silent Charge | The undeclared species of Charge: a stake debit posted to another seat without being made legible to them. Pairs with the Silent Veto as cause to effect — silent charges accumulate in the charged seat's balance and fire, eventually, as the Silent Veto. Its empirical signature is the flat-then-spike misrecognition curve: silent charges accrue invisibly and settle all at once, which is why they resist learning-from-experience — the feedback arrives detached from its cause, at a different seat and phase. A declared, prudent charge ("proceeding without clearance, review scheduled, redo risk accepted") is legitimate practice, not a Silent Charge — and earns more than avoided harm: declaration posts a credit to both accounts (the originator looks diligent; the gate-holder, a partner). | Charge species; candidate generator of the Silent Veto. [Open · n=0] |
The node lens — reading one role in isolation
| Term | Definition | Role / status |
|---|---|---|
| Node lens ★ | Reading each role's citation footprint on its own: what the assistant consults vs cites for that role's questions, and how its sources overlap (or don't) with the rest of the committee. | First diagnostic lens. [Open · n=3] |
| Consult-to-cite collapse | The assistant reads widely and cites a small, single-digit-percent curated subset. What survives is what the environment treats as authoritative enough to hand the buyer. | Why the cited set is the signal, not the read set. [Open · n=3] |
| Consulted-but-dropped | A third citation state beyond cited and absent: the assistant opened the page and chose not to use it — "in the room, looked at, declined." The most diagnostic state, and only visible if you read the consulted footprint. | Audit state; seeds the conversion fix-list (§6). [Open · n=1] |
| Citation Isolation | How little a node's cited sources overlap the rest of the committee's — the uniqueness of the citation space its choice points draw from. Measured over the cited set at the page / neighborhood (folder/subdomain) level, not registrable domain, on a locked run set. High isolation is competitive whitespace. | Node property. [Open · n=3] |
| The Isolate / the gatekeeper-unserved node ★ | The node that is both decisive (veto-grade) and one the brand-relevant commons doesn't reach — the first place to build, and the empirical fingerprint of the Silent Veto. High-leverage because it is the rare seat where the two committee-graph edge sets coincide (decisive veto + unreached citation space). Across all three worked committees it was the compliance / security / legal gatekeeper (make-a-logo → Legal; pharma → Quality; Industrial Computer Manufacturer → OT Security) — and, per the valence reading (§6), the low-valence, constraint-grounded seat, which is why its veto is hard and unservable by persuasion. Presents in three species, which set the build: (disjoint) isolate → enter; null isolate → create; consulted-but-dropped → convert. | Primary node-lens build target. [Open · n=3] |
| Null isolate | A gatekeeper that cites the empty set — isolation at the limit (Biopharmaceutical Company Quality: consulted six regulator domains, cited none). No corpus to enter, so you must create the citeable artifact. The strongest Silent-Veto fingerprint. | Node-lens sub-type; greenfield build. [Open · n=1] |
| The Sink ★ | The node with the most identical-page overlap and the most citations — build once and reach the convergent cluster at once. The Isolate's strategic opposite (easy to reach, thin on primary evidence vs. hard to reach, decisive). | Node-lens build target. [Open · n=1] |
| Read-volume / foraging intensity | How hard the environment foraged for a role and how little survived — the read→cite ratio and pages-per-domain. Caveat: a large near-uniform hub/aggregator share (~40%) means absolute counts are foraging breadth, not research depth; cross-role comparison still holds. | Node-lens read (consult side). [Open · n=1] |
| NodeWeight | The structured, phase-indexed, edge-directed profile of a node's decisiveness — replacing the earlier scalar "Weight." Six axes in three groups: magnitude (veto position + subtype; reversibility/consequence — now also fed by the valence of the node's choice points, §6) drives build-priority; type (which Apex cost dimension; which withheld reciprocity) shapes the response; temporal (phase-index; volatility) indexes the reading. Scored on the choice point (structural), never on the practitioner's internal state. | Replaces "Weight"; node-lens decisiveness. [Open] |
| Valence ★ | The number of viable directions that radiate from a choice point — the breadth of the live option space the practitioner faces there. High valence = many directions open (generative, exploratory); low valence = few, tending to binary (constrained, forced). Orthogonal to ambiguity (how many directions vs. how unclear which). Scored on the choice point's structure, never the practitioner's internal state. Feeds NodeWeight's magnitude group; sets the design move (§6). | Choice-point property. [Open · new] |
| Conditional / fragile citation | A node's citation can overstate presence: a source cited when the role is asked in isolation can collapse when the committee's actual colliding constraint is introduced. Single-role presence is an upper bound; the edge lens stress-tests it. The collapse has a flow-layer reading — the overlap alibi: citation footprints are proposition-blind (they establish shared foraging ground, not shared stakes), so shared or single-role presence manufactures a presumption of mutual legibility — "we both saw the same research" — masking charges that were never proposition-tested. High overlap does not prevent charges; it masks them. | AAudit caution linking node ↔ edge; the high-overlap charge mask. Collapse [Open · n=1]; the alibi reading [Open · n=0 — consistent with, not inheriting, the n=1 observation]. |
The edge lens — reading the friction between roles
| Term | Definition | Role / status |
|---|---|---|
| Edge lens | Reading the committee's edges: where two roles' criteria collide, and whether anyone owns the content that reconciles them. | Second diagnostic lens. [Open · n=1] |
| The Bridge ★ | The edge-level build target: content that connects a high-veto role to a high-traffic one across an empty citation edge — placed at the high-traffic end, carrying the veto-holder's concern. The discipline's name for an artifact-as-Translator (Doc 13): an artifact that travels into a room the originating practitioner is not in and does translation work on their behalf. Gauge: veto-dependency × citation-gap. | Edge-lens build target. [Open · n=2] |
| Matched-variant friction probe | The empirical instrument for the edge: ask one real cross-role collision three ways — each role alone (parallel), each forced under the other's constraint (chained), and a neutral arbiter (reconcile) — across two framings. The signal is the contrast between variants. Diagnoses the collision at Carlile's three boundaries — syntactic, semantic, pragmatic (§6) — the pragmatic boundary being where colliding interests live. | Edge-lens method. [Open · n=1] |
The trajectory lens — reading the decision over time
| Term | Definition | Role / status |
|---|---|---|
| Trajectory lens | Reading the decision as a process across the Decision Phases: who owns the cited answer at each phase, and where ownership hands off. | Third diagnostic lens. [Open · n=1] |
| Leakage point | The phase transition — where the buyer is handed from one source-world to the next and is most steerable, least defended. The trajectory-lens build target. | Trajectory-lens build target. [Open · n=1] |
| Convergence / the citation commons | A committee-level property: whether the non-gatekeeper roles converge on a shared authoritative core (a commons) or fragment. Citation isolation is field-dependent, not universal. Read as a diagnostic property of the graph, not as a collective the discipline serves (§3.2). | Committee-level graph-density property. [Open · n=1 convergent] |
Brand position — how the client sits in the landscape
| Term | Definition | Role / status |
|---|---|---|
| Presence concentration / load-bearing page | The degree to which a brand's entire cited presence collapses onto one asset (Industrial Computer Manufacturer: essentially one store page). The brand-side mirror of Citation Isolation. | Brand-position. [Open · n=1] |
| Entry phase | How late in the trajectory the brand first appears (Industrial Computer Manufacturer: absent until approach/selection). The brand-side mirror of the leakage point. | Brand-position (trajectory). [Open · n=1] |
| Presence breadth | Across how many roles / phases / surfaces the brand is cited versus absent. | Brand-position. [Open · n=1] |
Content, deployment, and measurement
| Term | Definition | Role / status |
|---|---|---|
| Choice-Point Content ★ | The work product: content shaped to serve a specific choice point — role-specific comparison framing, decision criteria, explicit tradeoffs, use-case proof, verifier fragments — and carrying readiness-affordances (staging, signaling, opt-in depth, disclosure, low-cost disengagement; §6). Phase-specific in form. | Tier 2 — what gets built. |
| Anchor Context | The ~350-word (~500-token) chunk surrounding a retrievable element that explains why it belongs in the answer to the choice point. Replaces Anchor Text as the unit of design. Maps to the five-element structure of the O2O Designer Protocol (Doc 18; §6). | Compositional unit of Choice-Point Content. |
| Query Fan-Out (QFO) | Query decomposition / multi-query retrieval: a complex prompt broken into sub-queries, each retrieving different Anchor Contexts. Each sub-query roughly corresponds to a choice point. | Retrieval-side counterpart to Choice Point. |
| Citation Optimization ★ | The deployment discipline: placing Choice-Point Content where AI search retrieves it, on owned and off-site surfaces. (Empirically, AI citation is overwhelmingly off-domain.) | Tier 3a. |
| Impact Tracking | The measurement loop: locked buyer-proxy prompt cohorts, baseline metrics, longitudinal repeat-run tracking. Its three metrics feed the numerator of PARSE's utility measure, POUI, in designer-internal work (§6). | Tier 3b. [Substantially Grounded] |
| Mention Rate / Citation Rate / Recommendation Rank | Does AI name the brand / link the domain / where does the brand place in an ordered list. | The three Impact-Tracking metrics. |
| Overlapping Zone of Utility | The space where content simultaneously serves the buyer's decision and an external citer's audience — the design discipline link-building forced. | Foundational design discipline. |
Friction vocabulary
| Term | Definition | Role / status |
|---|---|---|
| FUQ (Frequently Unasked Question) | A latent inquiry the practitioner carries but does not articulate. | See Foundations of the FUQ Model. |
| FLUQ (Frictive Latent Unasked Question) | A FUQ subtype whose social, cognitive, or symbolic friction prevents articulation. Canonical roster: four operational-primary mechanisms — CLUQ, SSQ, RDU, PTA — plus three acknowledged-but-not-yet-canonical mechanisms (IFQ, PFQ, BFQ) carried in the working paper (see §7). | Mechanism vocabulary for friction-diagnosis. |
A note on the FLUQ expansion: PARSE-canonical is "Friction-Inducing Latent Unasked Question" (Doc 16). The "Friction-Inducing" expansion that appeared in earlier industrial edge-compute material is the FILUQ domain variant (the same construct in a domain-specific form) and is footnoted as such rather than used as the headline name.
Several adjacent terms: Decision Axis, Axis of Advantage, AI Response Behavior, PARSE Apex Question, POUI, ΔS_d, and D-REC/Q-FIT/Z-GAP are defined in companion Citation Labs and PARSE materials and are not redefined here.
§3. The Decision Architecture Framework
Decision Architecture has accumulated several structuring ideas: tiers, functions, levels, lenses, phases.
They are not competing frameworks. They answer different questions, and the discipline reads cleanly only when each is held at its own altitude.
This table fixes them in place:
| Structure | The three | Question it answers | Altitude |
|---|---|---|---|
| Tiers | Audience Decision Context → Choice-Point Content → Citation Optimization + Impact Tracking | How the work moves (map → build → deploy & measure) | Workflow |
| Lenses | node · edge · trajectory | How you read the committee | Diagnostic |
| Levels | Choice Point → Node → Committee | What nests in what | Structural |
| Phases | Purchase Decisioning → Resource Planning → Benefit Maximization | When in the decision's life | Temporal |
One word does double duty: node is both the middle level (a role-holder treated as a unit) and the object the node lens reads. Same referent, two uses — not a conflict once named.
The rest of this section walks the pieces once, in that order. And §6 puts the lenses to work.
3.1 The foundation: decision, committee, functions, levels, phases and where the Apex is asked
Before content can be designed, the discipline asks: who is the practitioner, what decision are they inside, what functions does that decision require, and who holds them?
This is Audience Decision Context (Tier 1).
It is not a persona. Where persona models characterize the practitioner, Audience Decision Context characterizes the decision the practitioner is inside.
At its core sits the recognition that every decision requires the same six functions to be answered:
- Use: Engaging with the outcome daily (the people who live with the decision once made).
- Judgment: Evaluating fit-for-purpose.
- Authorization: Granting means and right to proceed.
- Defense: Justifying the choice afterward, to peers, partners, or future-self.
- Exposure: Carrying the stake (gain if right, loss if wrong).
- Transition: Moving the decision forward through its choice points; held by the Champion. The sequencing of those choice points is itself a choice point under this function. See the Champion entry (§2) and the flow layer (§3.2).
The functions are constant. The Role-Assignment Pattern that distributes them across human role-holders is substrate-specific.
- B2B SaaS commonly: Practitioner/Use, Technical Reviewer/Judgment, Budget Owner/Authorization, Executive Sponsor/Defense, Exposure spread across all, Transition concentrated in the Champion.
- B2C: Consolidates the six into one mind
- Healthcare: Distributes across patient, physician, family, payer
- Civic: Distributes across many voters with organized advocacy
The discipline nests in three levels: the Choice Point (the atom — one practitioner weighing evidence at one moment), the Node (a role-holder treated as a unit — and, crucially, a full practitioner in their own right: identity, schema, arc, finite metabolism, and their own object of practice), and the Committee (all the nodes for one decision).
Where the Apex Is Asked
The choice point is not only the atom of the discipline, it is the place where the discipline's parent framework, PARSE, asks its central question (§4.8):
Does this artifact's output meaningfully reduce the effort, ambiguity, or symbolic burden experienced by a real practitioner (mid-transition, within their actual theater of practice) as they steward an object of practice from state A to state B?
That question is asked at a choice point. This is why so much converges there: a practitioner's unasked questions (FLUQs), the phase they are in, the costs they are carrying, the veto they may levy, and even the hard constraints of their practice all show up at choice points.
The choice point is the discipline's evaluation locus.
One guardrail comes with that. Elevating the choice point must not displace the practitioner. The choice point is the unit of analysis and design (where you read and where you build). The practitioner remains the unit of service, the one whose stake the work exists to move, and whose authority over their own readiness is not the discipline's to override.
Keep the two distinct: you analyze at the choice point, you serve the practitioner.
To make a choice point legible rather than abstract, the discipline reads it through a Choice-Point Profile (§2): The practitioner's actual question out front, tagged with function, phase, valence, dominant cost dimension(s), veto character, FLUQ load, charge exposure (whose stake balances committing here debits, §6), and constraint-grounding.
The profile is what turns "Judgment" or "Exposure" (labels that read as abstractions on a slide) into something a practitioner or client recognizes as a real moment in their own decision.
Decisions unfold across three canonical phases: Purchase Decisioning, Resource Planning, Benefit Maximization, from Citation Labs' 2022 Buyer's Journey Link Building Worksheet.
Function-holding is phase-distributed: Authorization is acute at Purchase Decisioning and recedes; Use is dormant early and central from Resource Planning on; Defense peaks at Benefit Maximization.
The Champion role can transfer across phases. Which function-holder is acute when is the first thing the mapping surfaces. (The relationship between this three-phase model, the finer six-step cut used in the trajectory lens, and PARSE's own transition arc is reconciled in §6.)
3.2 The committee as a graph: a diagnostic over a single-practitioner framework
A committee is not just a list of role-holders; the discipline reads it as a graph. The nodes are the role-holders.
Two kinds of edges run between them:
- Citation-overlap edges (Shared cited ground): Do two roles' answers draw on the same sources?
- Decision-dependency/veto edges: Who can stop whose decision?
Decision-dependency/veto edges are the committee-spanning face of phase-distributed veto (PARSE Doc 13: veto authority is distributed across the decision's phases, not concentrated at the decision table).
These two edge sets are usually misaligned (a role can hold a decisive veto over another whose evidence-world it never touches) and that misalignment is exactly where the leverage lives.
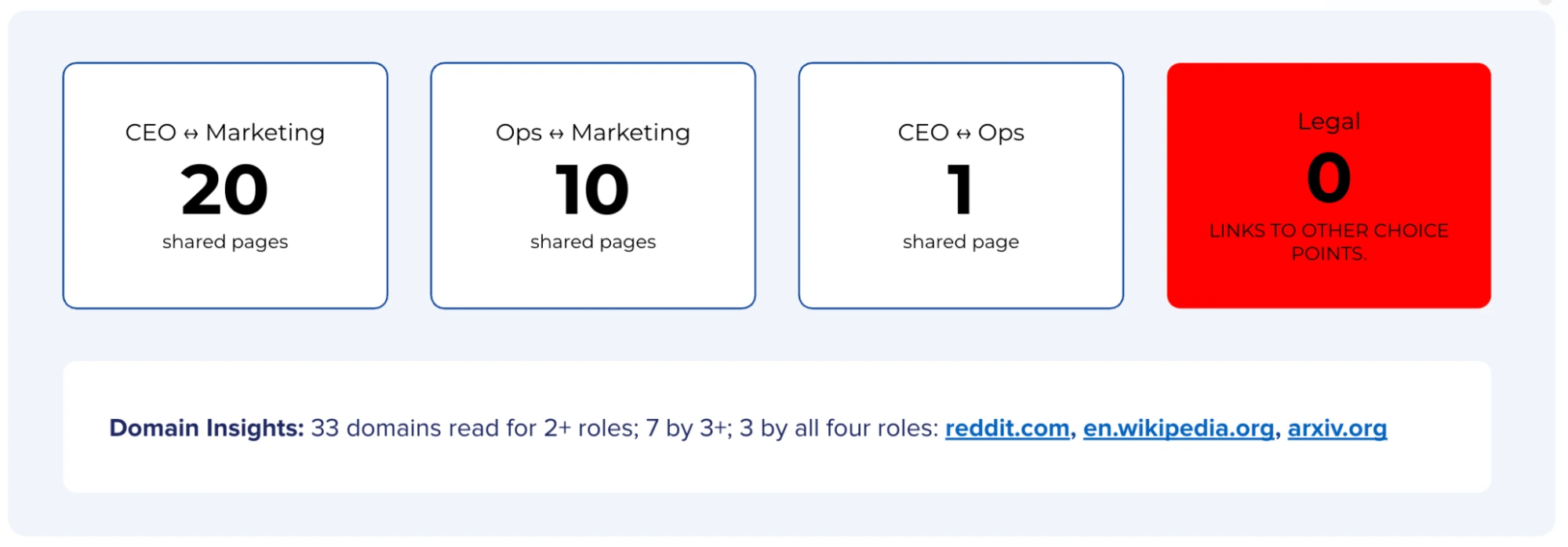
Naming the two edge types is what makes the node and edge lenses cohere. [Open · n=3 — the graph reading replicated across three applied committees: a consumer creative purchase, a regulated healthcare committee, and an industrial edge-compute committee.]
A Third Layer: Transactions on The Edges
The two edge sets are stocks and static relations. Running along the dependency edges is a flow (a Charge, §2): cost created at one seat's choice point and paid by another, later.
The committee's costliest dynamics are often transactional rather than structural, an upstream commitment posts a debit to a downstream seat's stake balance, and the debit settles (as rework, as a Silent Veto, as a Benefit-Maximization failure no one can place) long after, and somewhere else.
Charges originate in at least five ways, and the intervention differs by origin:
- Sequencing charges (order-dependent): Re-ordering converts silent to declared or removes the debit entirely. The remedy is re-sequencing (the clearance-brief pattern).
- Selection charges (content-intrinsic): The commitment's substance binds another seat under every ordering. The remedy is explicit-tradeoff disclosure at the choice point, already a Choice-Point Content property.
- Omission charges (null-origin): The unvisited choice point, with no commitment event at all, felt by the settlement instrument as a trace with no origin. The remedy is a roster audit.
- Standing charges (structural and non-transactional): The Role-Assignment Pattern itself as a charge generator, debiting the same seat by default across every decision the organization runs: the Persistent Information Gap's flow-layer twin, and largely accountability-layer territory beyond content's reach.
Standing charges have a formation mechanism, sedimentation: each silently accepted transactional charge re-prices the next one's declaration threshold, until the charge stream hardens into the Role-Assignment Pattern itself. Role creep, given a mechanism: transactional → standing.
- Conscription charges (off-graph): Being debited is what drafts a practitioner onto the committee, usually into Use or Exposure, without the assignment ever being a choice point they hold. The charge retroactively reveals a node the committee always had, and because a conscripted seat has no veto channel, its recourse arrives as the attritional veto in its own theater: non-adoption, churn, quiet burnout.
Across all five, sequencing is the universal modifier. It sets the silence and the interest, but it is only one origin of the principal.
Along any trajectory, the irreversibility nodes, where soft cost converts to hard (files cut, capital committed, contracts signed), are where the interest rate on outstanding silent charges inflects. They are distinct from the leakage point, which is a steerability property of phase transitions, though the two can coincide.
Declaration is most valuable upstream of them.
Citation overlap offers no immunity from any of the five.
At the Isolate, charges go silent because nobody looked into that seat's world. At high overlap, they go silent for the opposite reason: everybody believes looking was sharing.
Citation overlap is proposition-blind, so a shared footprint functions as a false declaration affordance. The overlap alibi (§2): the stake being debited was never the thing either party read those pages for.
High overlap does not prevent charges. It masks them. That is why the prediction of charge vectors inside a high-overlap pair runs on the function-cross and the proposition-level read (§6, edge lens, predictive mode), not on the overlap count.
The flow layer stays inside the N-Practitioners discipline: a charge is a pairwise, directional relation between two practitioners' situations, not a property of a collective.
The Champion, whose object of practice is the decision-as-a-whole, is the seat where the committee's net charge position comes to rest. Since sequencing is itself the Champion's choice point (§3.1), much of that position is self-originated.
A ledger implies a settlement record; reading that record is the settlement instrument (§6). [Flow layer and origination typology: Open · n=0 — theory frontier; make-a-logo is a latent instance, inferred from the late-veto cost shape rather than captured as a charge.]
What The Graph Is, And Is Not
It is a powerful way to see a multi-role decision. It is not a new kind of subject that the discipline serves. Under the hood, the committee-graph is a single-practitioner framework applied N times (PARSE's N-Practitioners reading, Doc 18, §8): every role on the committee is its own practitioner with its own object of practice, its own questions, its own stake.
The graph's committee-level properties (convergence, the citation commons, the coincidence of the two edge sets at the Isolate) are diagnostic readings of that field. They tell you which practitioner to serve first and where one build can reach several. They are not an emergent unit with its own apex. The practitioner stays the unit of service. The graph is the map.
The collective is nonetheless real, and it has a place: it rides as the object of practice of the Champion, the practitioner whose own decision is the whole reaching completion. "Serving the committee" decomposes into serving the Champion (whose OOP is the decision-as-a-whole) and each seat (whose OOP is its own slice).
Whether a committee-graph ever earns promotion to a genuine collective unit (a "PARSE-Collective") is a live, bounded question carried in §9 with the condition that would settle it; this version commits to the diagnostic reading.
3.3 The three lenses
A Decision Architect reads the committee-graph three ways. Each lens has its own diagnostic and its own build target.
- The node lens: Read each role alone. For each role, what does the assistant consult versus cite, and how isolated is its cited set? The diagnostic surfaces the Isolate: the node that is both decisive (veto-grade) and citation-isolated. Across all three of the worked committees it was the compliance/security/legal gatekeeper, the gatekeeper-isolate regularity that makes the Isolate predictable. [Open · n=3]
- The edge lens: Read the friction between roles. Where two roles' criteria collide (security wants a fleet patchable for a decade; procurement wants it frozen for seven years), is there content that reconciles them, and who owns it? The diagnostic is the matched-variant friction probe (§6). The build target is the Bridge, content placed at the high-traffic role's end of an empty citation edge, carrying the veto-holder's concern. [Open · n=1, edge lens fully exercised on industrial edge-compute only.]
- The trajectory lens: Read the decision over time. Run the same decision across the phases: does the choice architecture change as the practitioner moves through it? It changes completely, the owner of the cited answer hands off at every phase. The build target is the leakage point: the phase transition, where the practitioner is most steerable, least defended. [Open · n=1.]
These three lenses are read inside a committee-level property: convergence.
Some committees converge on a shared authoritative core. For example, a citation commons the non-gatekeeper roles cite (regulated healthcare: four of five seats on FDA/EMA) while some are disjoint (make-a-logo; industrial edge-compute).
Citation isolation is therefore field-dependent, not a universal law.
Convergence inverts the build strategy: in a disjoint committee you build per isolated seat; in a convergent one you win the shared commons and build for the gatekeeper by its species.
Even though the convergent case here is shallow and incomplete, §9 keeps the honest tag that there is no clean convergent committee in the set yet. [Open · n=1 convergent.]
3.4 The three tiers (the workflow the lenses serve)
The lenses are how you see. The tiers are how the work moves.
- Tier 1. Audience Decision Context: Who is deciding what (§3.1), populated through the three lenses.
- Tier 2. Choice-Point Content: The work product: content shaped to serve a specific choice point, with five structural properties at Purchase Decisioning (comparison framing, explicit tradeoffs, decision criteria, use-case proof, verifier fragments), phase-specific shapes later, and carries readiness-affordances (§6) so the artifact equips the practitioner to judge their own readiness rather than presuming it. Its compositional unit is the Anchor Context.
- Tier 3. Citation Optimization + Impact Tracking: Deployment and measurement. Citation Optimization places Choice-Point Content where AI search retrieves it—overwhelmingly off-domain. Impact Tracking closes the loop: locked buyer-proxy prompt cohorts, three metrics, and longitudinal repeat-run tracking. [Impact Tracking: Substantially Grounded, see §5, §9.]
The tiers compose as:
Who the work serves → What it produces → How it deploys and measures
They cohere only when a Decision Architect holds the whole, reading the committee through the lenses, building for the targets each reveals, and measuring whether the build moved the citation environment.
§4. Theoretical Lineage
Decision Architecture is not a wholly novel discipline. It synthesizes and applies several established traditions, and most load-bearingly, it is an application of PARSE (§4.8).
The synthesis is the contribution. This section names the debts so future practitioners can trace the foundations rather than rediscover them.
4.1 Choice Architecture (Thaler & Sunstein)
The most direct intellectual sibling and a term to keep carefully distinct. Thaler and Sunstein (2008) introduced choice architecture as the design of the environment in which a single choice is made: defaults, ordering, friction, nudges.
Decision Architecture inherits the spatial metaphor and the design-the-environment posture, but departs in scale and protagonist. It designs around the constellation of choice points that compose a real decision.
The relationship is generative: a Decision Architect uses choice-architecture insights tactically within choice-point content while working the layer above.
Throughout this treatise "choice architecture" refers to Thaler & Sunstein's construct. It is never a synonym for Decision Architecture.
A second naming firewall is needed against the decision intelligence/decision science/decision engineering cluster (Kozyrkov and others), which designs the decision process inside the deciding organization.
Decision Architecture designs the content and source-set environment around an AI-mediated buying committee. They share a word and little else, but because the collision is close, the distinction is worth stating plainly.
4.2 Information Architecture (Morville & Rosenfeld)
The predecessor discipline. IA organizes content for findability and wayfinding. Its protagonist is the user navigating. Its success criterion is finding.
Decision Architecture positions next to IA as a sibling, not over it: IA gets the practitioner to the right page. Decision Architecture makes that page sufficient for the choice point once they arrive.
The sibling positioning is also strategic, giving Decision Architects intellectual furniture to stand on rather than building from scratch.
4.3 Communities of Practice (Wenger, Lave)
The audience-defining frame. The 2011 Citation Labs article 5 Key Units of Expertise translated this into a content frame: practices produce communities; communities have gaps that drive search.
The discipline inherits the audience claim: the audience is never an individual abstracted from their practice.
4.4 Jobs To Be Done (Christensen, Ulwick)
Adjacent thinking about customer jobs. The discipline borrows JTBD's focus on the practitioner's actual work and its skepticism of features-as-positioning. It departs in the subject of design.
JTBD informs product design. Decision Architecture applies the job lens to content and source-set design for AI-mediated discovery.
4.5 Bonoma's Buying Center
The procurement-literature anchor. Bonoma (HBR, 1982) introduced the Buying Center and the insight is almost universally lost since. The formal org chart understates who actually holds purchase decisions.
Citation Labs' 2023 work built directly on Bonoma. The six-function decomposition is the further abstraction. Where Bonoma named roles, the discipline names functions.
(The gatekeeper-isolate finding in §6 is a measurement-era vindication of Bonoma's core point: the role with the most decisive, least-visible veto is often the one the org chart underweights and now it shows up as the citation-isolated node.)
4.6 Service Design
The journey-mapping discipline (Stickdorn et al., 2018) emphasizes multi-touchpoint experience across the whole journey.
The discipline inherits its temporal-phase posture (part of what makes Decision Phases and the trajectory lens feel structurally natural) and applies the sensitivity to content and source-set design.
4.7 Implementation Science (CFIR, NPT)
For how new disciplines get adopted. CFIR and Normalization Process Theory study what makes interventions actually get used. This is relevant to how Decision Architecture spreads from discipline-on-paper to discipline-in-practice within client organizations.
Reading through the flow layer (§3.2), implementation science also acquires a second face: NPT and CFIR are the science of helping conscripted practitioners metabolize a decision they did not make, which is what down-funnel "hold" content has been doing all along.
4.8 PARSE — the parent framework
This is the substrate the rest of the discipline stands on, and it is worth stating in full, because most of what can look in this treatise like freshly-minted vocabulary is an application of something PARSE already holds.
PARSE (Practitioner-Aligned Return on Staked Effort) evaluates whether a communicative artifact has earned the right to be deployed, by the return it generates for a real practitioner.
Its constitutional anchor is the Apex Question: does this artifact's output meaningfully reduce the effort, ambiguity, or symbolic burden experienced by a real practitioner — mid-transition, within their actual theater of practice — as they steward one or more objects of practice from state A to state B?
Decision Architecture is the externally-facing translation of that question into a discipline name that SEO and content practitioners can adopt without first absorbing the whole framework and, per PARSE's own translation principle, the framework vocabulary stays in the designer's hands while the practitioner-facing artifact speaks the practitioner's language.
The alignment is exact at several joints:
- The Apex is asked at the choice point (§3.1). That is the hinge between the two frameworks: a choice point just is a practitioner, mid-transition, meeting an artifact. This is why the choice point "feels like the whole thing". It is where PARSE's anchor operates.
- POUI, kept designer-internal. PARSE operationalizes the Apex as the Practitioner-Outcome Utility Index (return over a friction denominator). The discipline keeps POUI in the internal artifact (the audit, the brief), not the client deliverable. The three Impact-Tracking metrics (Mention, Citation, Recommendation Rank) are read as inputs to POUI's numerator rather than as the whole of value.
- The cost model is the Practitioner Friction Signature. PARSE's three Apex burden dimensions (effort, ambiguity, symbolic burden) are the apex of the cost model, and under them sits the Friction Signature (narrative, symbolic, cognitive, role-based misfit). §6 uses these to decompress what had been an over-compressed three-bucket cost read.
- Readiness is the practitioner's, not the architect's. PARSE holds that you cannot assess a practitioner's readiness from outside; what you can do is design readiness-affordances: staging, signaling, opt-in depth, disclosure, low-cost disengagement. This is why NodeWeight scores the choice point's structure, never the practitioner's internal state, and why Choice-Point Content carries affordances rather than presuming readiness (§6).
- Silent Veto and the Bridge have canonical parents. The Silent Veto is the continuous/attritional subtype of phase-distributed veto (Doc 13); the Bridge is an artifact-as-Translator (Doc 13), an artifact that travels into a room the originating practitioner is not in and does translation work there. The edge lens diagnoses the collision it bridges at Carlile's three knowledge boundaries (Carlile 2002, 2004): syntactic, semantic, and pragmatic, the last being where colliding interests actually live.
- The committee-graph is Ring 1 applied N times. PARSE reserves a PARSE-Collective for genuine multi-party units, and explicitly has not built it; the discipline stays inside the single-practitioner framework, reading the committee as N practitioners (§3.2).
One more PARSE discipline travels into the practice and is worth naming, because it governs how a Decision Architect should treat the people on a committee. Assume good faith in how you treat a practitioner; model self-interest in how you analyze them.
Practitioners carry private ledgers (status, hidden agendas, their own stake) that diverge from their professed collective rhetoric. The discipline should model that divergence (it is what the veto edges and the gap between assigned and enacted role are for). But it does not try to read the heart from outside, the same category error as scoring readiness from outside.
The operational answer to a motive you cannot verify is not suspicion. It is to design affordances robust to that uncertainty: keep the practitioner's judgment intact, expose the reasoning so it can be audited, keep disengagement cheap.
Self-interest is not bad faith, and a Decision Architect who conflates the two goes adversarial and manufactures the resistance they feared.
4.9 Eric Ward's Link-Worthiness Tradition
The mentor lineage. Eric Ward established the thesis that useful content gets linked. Where Ward asked what makes content useful enough to earn citation, Decision Architecture asks what makes content useful enough to earn citation for a specific decision by a specific committee at a specific moment.
Same root question; refined unit. The 2015 webinar Garrett co-presented with Ward and Shari Thurow articulated linker-valued audiences versus buying audiences—the seed of the plurality discipline and the Overlapping Zone of Utility.
4.10 Technical Debt (Cunningham; Fowler)
The charge's nearest lineage. Cunningham's 1992 debt metaphor and Fowler's quadrant name the structure the flow layer describes: cost taken on now and paid (with interest) later.
Principal and interest translate cleanly: the charge is the principal; the misrecognition that compounds between charge-time and settlement-time is the interest, which sharpens the "late no" figure's caption to “what it costs depends on how long the charge sits undeclared.”
One adaptation is required: Fowler's quadrant is indexed on intent (deliberate/inadvertent × prudent/reckless), while the discipline scores structure (legibility × declaration).
It imports the quadrant's insight (debt can be legitimate, and the reckless-undeclared cell is the failure) without its intent axes. The vocabulary is also a two-register gift: "technical debt" is practitioner-native for technical substrates, a ready translation of the charge.
4.11 Convergence
Across these traditions, three principles converge:
- The audience is plural and situated.
- The unit of design is the decision moment, not the artifact.
- The deployment surface matters but does not define the discipline.
Decision Architecture synthesizes these (on a PARSE foundation) into a discipline with operational substance.
§5. The Origins of Decision Architecture
Decision Architecture emerged from fifteen years of Citation Labs work. It was discovered through practice and named afterward.
- 2011: Practice produces communities. 5 Key Units of Expertise named expertise as something that emerges from practice. The audience for content is a community of practice with shared gaps.
- 2015: The plurality discipline. A live webinar with Eric Ward and Shari Thurow articulated the linker-valued audience as distinct from the buying audience. Link building forced the plurality discipline, the overlapping zone of utility.
- 2017: The audience definition lands. On a whiteboard at audiential.com: "audience (practitioner within a domain of practice) engaged in an action cycle with the entity of practice." The foundational claim of Audience Decision Context.
- 2018: The Practitioner Action Cycle. Building Links to Sales Pages named the Practitioner Action Cycle and introduced Object of Practice and Theater of Practice. Towards Market Mutualism put efficiency-for-the-other at the center.
- 2020: Each task has a cost. A whiteboard landed the task-cost frame: frequency, intensity, duration, outcome certainty, selection control, difficulty, visibility, urgency. The operational seed of Choice-Point Content's purpose.
- 2021: The architecture stack. Iterative whiteboards articulated a six-layer architecture beneath Audience Decision Context.
- 2022: The buyer's journey gets three stages and the FUQ enters in lexical embryo. Buyer's Journey Link Building articulated Purchase Decisioning → Resource Planning → Benefit Maximization and contained the earliest in-corpus appearance of "frequently UN-ASKED questions."
- 2023: The committee gets named. Three articles canonically named the decision-committee construct: measurement-as-stakeholder-equipping (January), the Benefit/Purchase Decision Stakeholder distinction (June), and the Purchase Decision Committeewith explicit debt to Bonoma, the canonical Champion, and the eight-dimensional cost taxonomy (November).
- 2025: The vocabulary catches up. At World IA Day and BrightonSEO, Citation Labs presented FUQ → FLUQ publicly.
- 2026: The discipline names itself and gets a measurement instrument. At SEL with James Wirth, the measurement instrument was articulated: the 4,579-prompt study (Presence Rate stabilizes across repeat runs), the off-domain controlled test, and the 306-microsite case study. By May 2026 the umbrella name had settled: Decision Architecture.
- 2026 (mid-year): The committee becomes a graph and the discipline is re-seated on PARSE. Applied engagements turned the committee into a measured graph via the soil-sample method, producing the node/edge/trajectory lenses, the Isolate, NodeWeight, the Bridge, and the convergence reading. The same period's PARSE-alignment work established that these constructs are applications of PARSE's own: phase-distributed veto, artifact-as-Translator, the N-Practitioners reading. It also seated the committee-graph as a diagnostic over a single-practitioner framework rather than a collective. This is the youngest layer; §9 marks which parts rest on one committee versus three.
§6. What a Decision Architect Does
The work is spined on the three lenses.
- The arc: audit the prompt that frames the question (Move 0); read the citation landscape (the soil-sample audit).
- Read it through the node, edge, and trajectory lenses; decide what to build; deploy it.
- Run the proof-loop.
The steps iterate in mature practice, but the sequence is the right place to start.
The run-card (one page)
| Step | Do | Input | Stop when |
|---|---|---|---|
| 0. Audit the prompt | Confirm no prompt names the brand/competitor; record framing biases | The buyer-proxy prompts | Prompts are organic and biases logged |
| 1. Soil-sample | Run each role's real questions; capture consult vs. cite | One shared scenario, role-voiced | Each role has a read/cite footprint |
| 2. Node lens | Score each node's Citation Isolation + valence; find the Isolate | The footprints | The decisive, unserved seat is named |
| 3. Edge lens | Run the matched-variant probe on one real collision | The colliding pair | The Bridge target is located |
| 4. Trajectory lens | Run the decision across phases; find the leakage point | The phase grid | Hand-offs and the entry phase are mapped |
| 5. Convergence read | Decide disjoint vs. convergent — which field am I in? | The cross-role overlap | Build strategy is set |
| 6. Build | Isolate / Sink / Bridge; satisfy low-valence, orient high-valence | The lens read | One asset per build pole is briefed |
| 7. Deploy + prove | Place off-domain; baseline → seed → re-run → measure lift | The buyer-proxy cohort | Lift (or its absence) is measured |
Move 0: The prompt is the primitive
Before any metric, audit the prompts.
The prompt is the framing of the decision question, and framing determines which options and authorities become salient. Read a citation metric without auditing the prompt and you are measuring your own framing, not the practitioner’s environment.
The audit pays for itself twice. First it establishes validity: confirm that no prompt names the brand or a competitor, so "who gets cited" is organic. Second it surfaces the framing biases you must carry as caveats.
Two disciplines hold the rest of the practice honest:
- Framing-invariance (run more than one framing of each role's question and trust the invariants, not the artifacts of any single frame).
- Data-grade reconciliation (recompute every cited count from the raw export against a second copy).
Two further warrants complete the epistemics:
- Contrast-as-signal: a single run tells you little; the measurement is the delta between matched variants (parallel vs. chained, spec-literate vs. plain). Read contrasts, not runs.
- The role-frame caution: the same discipline's question-side face: the observed fan-out is filtered by the voiced role's frame: the assistant unpacks the room you're in, not the room you don't know exists, so a role-blocked or identity-filtered question is missing from the fan-out by the same mechanism that keeps it out of tickets.
FLUQ recovery therefore lives in the choice of cohort: voicing every seat, including the Isolate's, is the FLUQ control, not a convenience. [Warrants: field-practiced; the role-frame face Open · n=0.]
The soil-sample audit: reading the citation landscape
A high-consideration decision is resolved by a committee. Each role carries a different question. Running each role's real question through an assistant and capturing what it consults versus what it cites yields a "soil sample" of the decision's terrain.
The unit of probing is the role (node). And each role gets two prompt lanes:
- The breadth lane: the role's three-to-four real concerns at once.
- The kill-switch lane: a lean, consequence-shaped prompt: "what's the one thing that, if we get it wrong, we can't undo, and what would make me say no?"
The kill-switch lane carries flow-layer weight. It surfaces each seat's irreversibility condition and tests whether the model can source it, making it the empirical harvest for weight-disclosure.
It also produces (per seat) the gate's finality and failure-cost in the seat's own voice, exactly the raw material the Bridge's motivation face compresses (§6, What to build) and the charge-exposure field records (§2).
Three design rules make the data comparable: retrieval-shaped, not advice-shaped; one shared scenario across all roles; and role-voiced, first person.
Two counting disciplines govern the read: the consult-to-cite collapse (the surviving subset is the signal), and count at the page and neighborhood level, not the registrable domain (domain-level counting collapses real differences and lets high-volume sites dominate).
One PARSE discipline governs interpretation: defer to the theater.
The Theater of Practice (the relational, temporal, ritual field the answer lands in) is determinative, not advisory. It is read in five dimensions (temporal alignment, feedback density, stake traceability, return concreteness, stake diffusion).
The single most important thing the soil sample tells a client is which kind of field they are in— you cannot read that from a generic playbook.
The node lens: read each role alone
For each role, map its cited footprint and its Citation Isolation: how little its cited sources overlap the rest of the committee's, measured at the cited/neighborhood level on a locked run set.
High isolation is competitive whitespace.
The diagnostic surfaces the gatekeeper-unserved node: decisive and unreached. Across the three worked committees it has been, every time, the compliance/security/legal gatekeeper:
- Make-a-logo → Legal
- Regulated healthcare → Quality
- Industrial edge-compute → OT Security
The leverage is structural: the committee-graph's two edge sets (citation-overlap and veto) are usually misaligned, and the gatekeeper-unserved node is the rare seat where they coincide. [Open · n=3.]
The gatekeeper presents in three species, which set the build: (disjoint) isolate → enter; null isolate (a gatekeeping function cites the empty set) → create; consulted-but-dropped (a relevant function is read and declined) → convert.
Why This Seat, Every Time: A Proposed Mechanism
The gatekeeper's stake is the least experientially shared on the committee: almost no other seat has ever lived the defend-against-the-regulator stake. [Open · n=0; the n=3 regularity's tag is unchanged.]
Experiential illegibility produces both fingerprints at once: citation isolation (nobody researches into that seat's world) and silent-charge accumulation (every seat debits its account unknowingly; §2).
If it holds, the mechanism explains why the committee-graph's two edge sets reliably misalign at exactly this seat, and it predicts where the pattern generalizes: any seat whose stake is rarely lived by others (procurement, an HOA, a spouse) will show isolation and charge-accumulation together.
The settlement instrument (below) carries the test: rate each charged seat's stake-experience sharedness; the mechanism predicts isolation and traced charges co-vary with low sharedness, and a committee whose gatekeeper stake is widely lived showing undiminished isolation would falsify it.
Read Friction as Signal, Not Just as Cost
Before treating the Silent Veto as an obstacle to overcome, read it.
A role's non-engagement is often an intelligent adaptation telling you something true about the offering's fit, not mere absence. The attritional veto is the practitioner's feedback. The node lens is how you hear it in citation data.
A role's decisiveness is profiled by NodeWeight (not a scalar, but six axes in three groups):
- Magnitude: Veto position + subtype; reversibility/consequence and the valence of the node's choice points, below.
- Type: Which Apex cost dimension is loaded; which withheld reciprocity is decisive.
- Temporal: Phase-index; volatility.
It scores the choice point, never the practitioner's internal state.
Example: regulated healthcare Quality & Compliance (Worked NodeWeight read):
- Magnitude: Holds a decisive, low-reversibility veto (a quality/compliance "no" stops the trial). Its choice points are low-valence (compliant/not binary, constraint-grounded).
- Type: The loaded Apex dimension is symbolic-and-effort (audit-defensibility), and the decisive withheld reciprocity is evidence the environment can source. There is none.
- Temporal: Acute from approach through validation; low volatility (the constraint doesn't soften).
The profile reads "build here first, greenfield" without averaging to a single number, which is the compression NodeWeight exists to undo. And because NodeWeight scores the structure and not the person, it never adjudicates whether the Quality lead is right, only how decisive their seat is.
Challenging a wrong Champion's vision is separate work, and belongs to the BFQ discipline (§7).
Three further reads sharpen the node lens:
- Read-volume/foraging: The read→cite ratio flags the most diffuse, consolidation-ripe space (The regulated healthcare CMO/CRO read 334 URLs and cited 3.6%), and pages-per-domain separates "foraged hard, found nothing citable" (regulated healthcare Quality: deepest forage, most regulator-heavy, cites zero) from shallow skimming. [Open · n=1.]
- Consulted-but-dropped names the brand pages in the room and getting declined, the direct input to a conversion fix-list. [Open · n=1.]
- Subdomain decomposition: yields epistemic distance + the authority gradient: distance (two roles in docs. vs developer. are not close); and a gradient where free-publishing authorities (NIST, the EU CRA) are reached at the primary source while paywalled ones (IEC) force proxies and explainer-rings, the unowned ground a brand can occupy. [distance Open · n=3; gradient Open · n=1.]
The edge lens: read the friction between roles
Real committee decisions turn on the friction between roles whose criteria collide.
The empirical instrument is the matched-variant friction probe: take one genuine cross-role collision (security needs the fleet patchable for a decade; procurement needs it frozen for seven years) and ask it three ways, each role alone (parallel), each forced under the other's constraint (chained), and a neutral arbiter (reconcile) across two framings.
The signal is the contrast between variants.
The collision can be diagnosed at Carlile's three knowledge boundaries:
- Syntactic (the roles lack a shared lexicon)
- Semantic (they read the same words to different meanings)
- Pragmatic (their interests and operational realities genuinely conflict).
The pragmatic boundary is where most cross-role committee friction lives, and it is the one a content fix can least paper over, which is why the build target is a translator (not a clarifier).
That build target is the Bridge: content placed at the high-traffic role's end of an empty citation edge, carrying the veto-holder's concern, so the veto is injected where the looking already happens.
In framework terms, it is an artifact-as-Translator: it does the veto-holder's work in a room the veto-holder is not in. Its gauge is veto-dependency × citation-gap.
The probe also exposes conditional/fragile citation (single-role presence is an upper bound that drops when the colliding constraint is introduced), and a deeper PARSE diagnostic worth running at the edge: the internal/external ledger mismatch, a brand cited as high-utility for one role can fail catastrophically at the edge because it satisfied that role's ledger while violating the colliding role's.
In practice the reconciliation surface is owned by an ecosystem (standards bodies, frameworks), not a vendor, so the Bridge is rarely greenfield. It is earning your way into an existing authority structure on its own terms. [Open · n=1.]
The edge lens (predictive mode) where will A's commitments debit B?
The edge lens also runs forward. Two halves predict the charge vectors inside any pair, including (and especially) high-overlap pairs the overlap alibi protects (§2, §3.2).
The function-cross: even at total citation overlap, the six functions guarantee stake divergence, so the dyad's charge map is (functions A holds) × (functions B holds) over shared commitment objects from the make-a-logo tables.
The CEO's Judgment commitment (what makes it credible?) predictably debits Marketing's Use stake (what makes it perform?), and the reverse vector runs from Marketing's performance optimization into the CEO's Exposure stake (do we look fundable?), both masked by twenty shared pages.
The proposition-level read: for each shared page, which claim does each role cite it for; where the propositions diverge, the charges run.
Two preconditions license the instrument:
- Resolution: Overlap is read on a three-rung ladder: domain → page/folder → proposition, each rung an upper bound on the one below.
On big sites, two roles "sharing a domain" are often in different sections entirely. As such, domain-level metrics can manufacture the overlap alibi at the instrument layer.
Routine audits run at page/folder minimum (the existing counting rule). Charge prediction runs at the proposition rung. Domain figures are reported only as ceilings. - The scenario lock (stated with its warrant): One shared scenario per committee-phase (already a soil-sample design rule) is the controlled-comparison license for every cross-role read: the shared-page matrix, the function-cross, and the proposition read are meaningful only when the commitment object is held fixed, so that the only thing varying is who's asking.
[Function-cross: Open · n=0 — runnable from existing make-a-logo data. Proposition read: extension of the n=1 matched-variant probe. Resolution and lock: field-practiced method rules.]
The trajectory lens: read the decision over time
Run the same decision across the phases and ask: does the choice architecture change as the practitioner moves through it?
It changes completely. The owner of the cited answer hands off at every phase. The build target is the leakage point: the phase transition, where the practitioner is most steerable, least defended.
The trajectory lens uses a finer six-step cut than the three canonical phases. The two map as follows, and both sit under PARSE's own transition arc:
| Canonical Phase (2022) | Six-Step Trajectory cut | PARSE Transition Arc |
|---|---|---|
| Purchase Decisioning | problem-framing → approach → selection | fracture → suspension |
| Resource Planning | validation → operate | realignment |
| Benefit Maximization | renew | integration |
One caveat travels with the lens: real transitions are not always linear.
PARSE flags non-linear, looped, and goal-changing arcs as the case its phase models handle least well. A practitioner can return to problem-framing mid-validation, and the trajectory read should expect it rather than force a straight line. A brand concentrated in one phase is defending a narrow spike in a journey otherwise owned end-to-end.
The growth is to intercept earlier and hold later. [Open · n=1.]
The altitude discipline: when to stop mapping
The lenses run at two altitudes:
- Zoom-in (node, edge) ends on a specific citable surface and a specific gap; it produces prescriptions.
- Zoom-out (trajectory, role × phase) produces targeting, where to play, not what to say.
Both are legitimate. The discipline is to remember that mapping the decision environment is necessary but not sufficient. The deliverable is the intervention.
Keep mapping only while each map sharpens the targeting, then convert: a map that no longer changes a build decision has stopped reducing anyone's effort, ambiguity, or burden.
The composed instrument (prompt-as-frame, matched variants, the three lenses, data-grade verification) is portable: the same apparatus instantiates for any client whose practitioners open with an assistant.
The settlement instrument: read who pays, and when
The lenses above read stocks and structure. The flow layer (§2, §3.2) needs its own reading, and the data already exists: customer-service logs are a settlement ledger.
The method is charge-provenance tracing: take a late-phase ticket and trace it back to the originating choice point and the seat that posted the charge.
These are often future-phase decisions (buy now, pay later), the committee's analogue of technical debt (§4).
It extends the trajectory lens from who owns the cited answer at each phase to who pays at each phase.
And it upgrades the friction taxonomy's "Benefit-Maximization failure no one can explain" (§7) into a mechanism: no one can explain it because the explanation lives at a different seat and an earlier phase.
Commercially, a settlement audit pairs with the soil-sample audit as a second entry diagnostic, read from data the client already has.
The pilot that would move this off the frontier: pull one client's support log, sample the Benefit-Maximization-phase tickets, and trace each to an originating choice point and charging seat, tagging each trace with its origin type (re-orderable/content-intrinsic/null-origin/structural/off-graph; §3.2) and the charged seat's stake-experience sharedness (§6, node lens).
If a meaningful fraction traces cleanly, the construct has field evidence. The origin distribution adjudicates how dominant sequencing actually is. And the sharedness ratings test the experiential-illegibility mechanism. [Open · n=0 — instrument specified, unrun.]
The convergence read: which strategy applies
Read whether the committee converges on a shared authoritative core (a commons the non-gatekeeper roles cite; regulated healthcare: four of five on FDA/EMA) or is disjoint (every role in its own world).
The build strategy inverts on it: disjoint → build per isolated seat; convergent → win the commons and build for the gatekeeper by its species.
The single most important thing the audit tells a client is which kind of field they are in. (Caveat carried to §9: the one convergent case is shallow and its gatekeeper a void, so the convergent end is effectively unproven.) [Open · n=1 convergent.]
Valence and what it predicts
A property runs underneath all three lenses and deserves to be read explicitly: a choice point's valence, the number of viable directions that radiate from it.
High valence is open and generative. Low valence is closed, tending to binary.
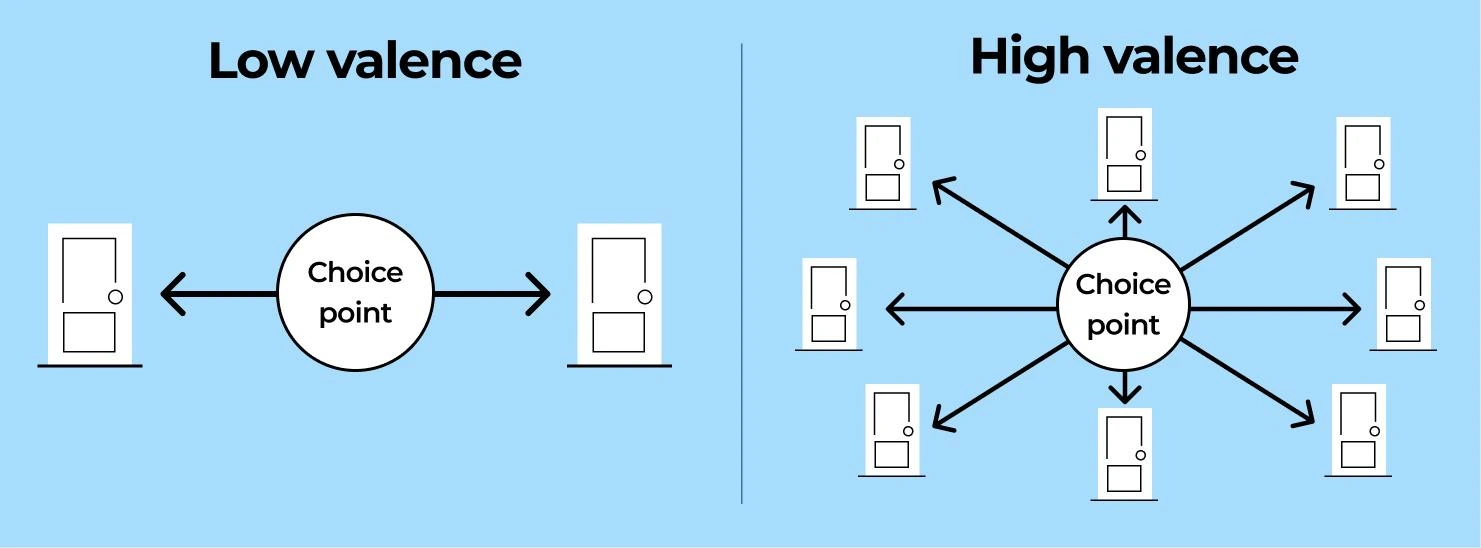
Valence is orthogonal to ambiguity (how many directions versus how unclear which) and the two together decompose what "ambiguity cost" actually is at a given choice point: many directions plus a poor schema is high ambiguity. Many directions plus a rich schema is simply rich choice.
Valence is scored on the choice point's structure, never the practitioner's state, and aggregated across a node's choice points it feeds NodeWeight's magnitude group. [Open · new.]
The Valence↔Constraint Hypothesis [Theory Frontier: Pre-Measurement]
Low valence is the signature of a hard constraint collapsing the option space.
The fewer the live directions, the more a real constraint (physics, regulation, spent resource) is collapsing, and the more the choice is governed by the external ledger rather than the practitioner's internal/symbolic one.
The sofa that simply will not fit up the stairwell is valence→1, decided by geometry. Legal's "compliant/not" is valence-low, decided by regulation. The classic-car buyer's "what does insuring this car mean" is valence-high, governed by symbol, which is exactly why that offering's benefit is obscured: nothing physical is forcing the choice closed.
Two payoffs follow:
- Prediction: the hard, decisive vetoes cluster at low-valence choice points, which is why the gatekeeper-isolate is always the compliance/security/legal seat, and why its veto is unservable by persuasion. You cannot argue physics or regulation open.
- Prescription: the design move the practitioner can act on. At low valence, satisfy/clear the gate with binary-passing evidence on the constraint’s own terms. Not a conversation, a clearance. This is why the null isolate needs created evidence. At high valence, orient/narrow: help the practitioner converge out of an open field toward their real object of practice.
One decomposition before the measurement runs [v0.8 amendment]:
Observed valence at a seat decomposes into intrinsic valence (constraint-grounded: regulation, physics, spent resource) minus sequencing-imposed reduction, a valence debit: a Charge (§2) whose debited stake is the seat's option space.
Positioned early, a gate seat is formative, advising among live candidates. Positioned late, it is terminal, pass/fail on one.
Low observed valence may therefore signal a hard constraint or a late sequencing position, and part of the gatekeeper's observed low valence may itself be sequencing-imposed rather than intrinsic, which is testable.
The measurement that would move the hypothesis off the frontier, amended with the control: across worked committees, does veto-decisiveness correlate inversely with the intrinsic valence of the seat's choice points, scoring each seat's valence both at its actual sequencing position and at the earliest feasible position, with only the intrinsic component bearing on the hypothesis? [Valence debit: Open · n=0.]
What to build
The lenses converge on three build poles:
- The Isolate: Build for the decisive, unserved node first (whitespace + veto; the gatekeeper). The clearest moat.
- The Sink: The node with the most identical-page overlap and the most citations. Build once and reach the convergent cluster at once. The Isolate's strategic opposite.
- The Bridge: Connect a high-veto role to a high-traffic one across the empty citation edge.
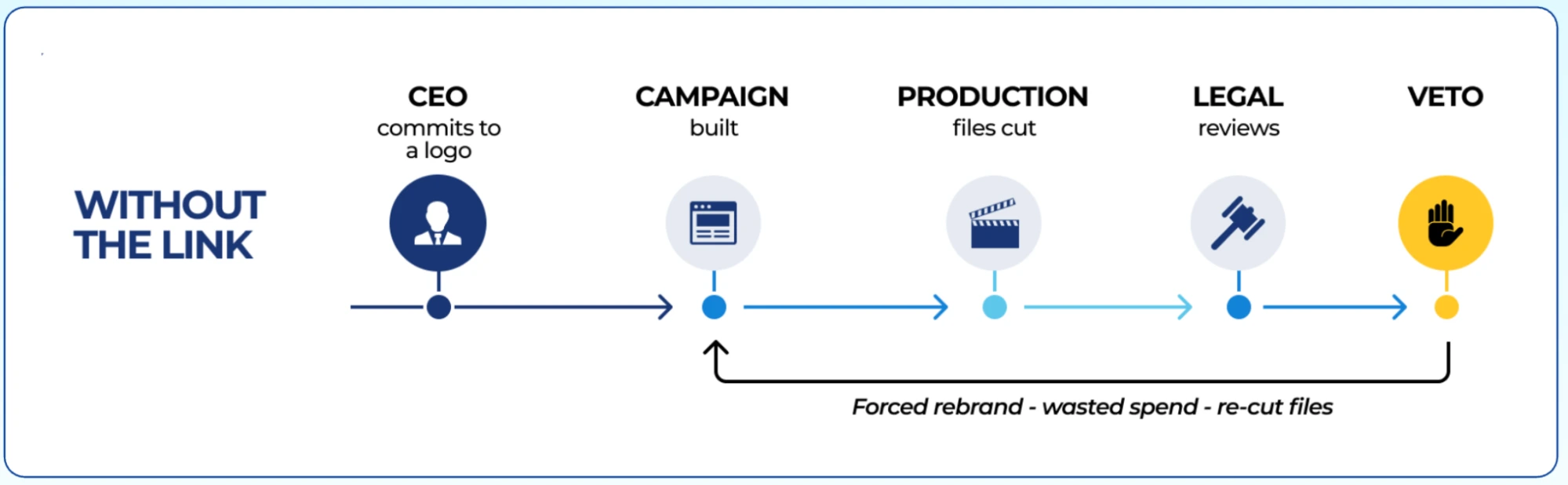
The Bridge has two faces: an execution face (the clearance brief: what the originating role must collect) and a motivation face (weight-disclosure: the charged gate's finality, substrate, and the cost-shape of failing it late, which is what makes upfront clearance rational at commit time).
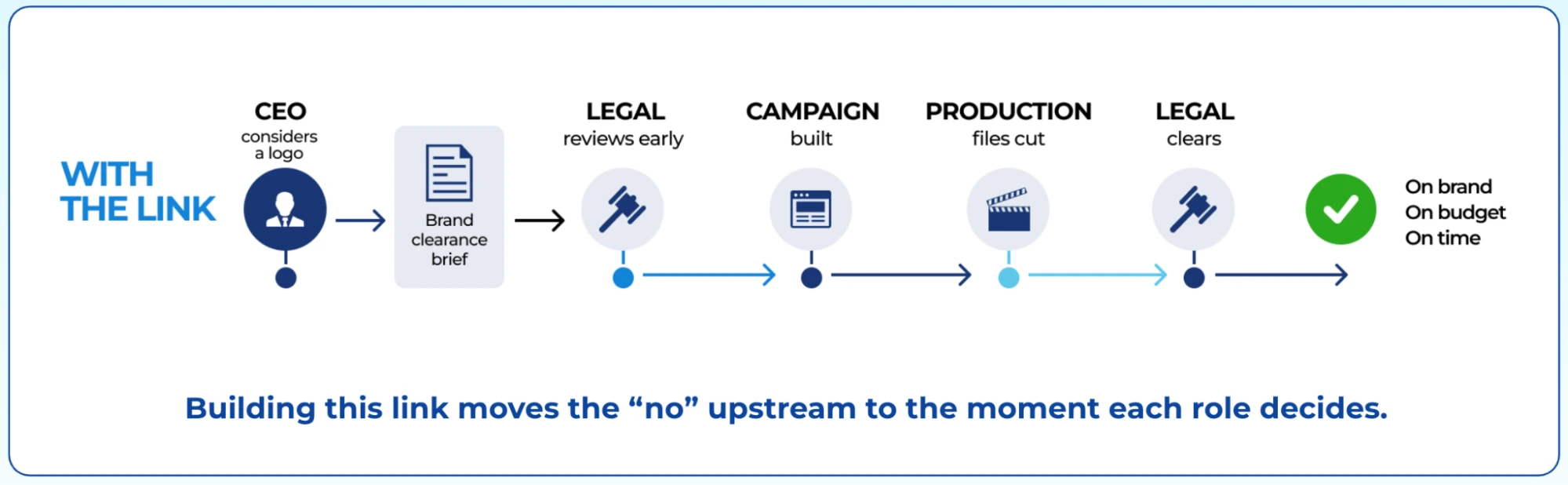
Execution presupposes motivation and the motivation face's full job description is a stake-experience prosthetic: the hard half of legibility is weight-legibility (§2), ordinarily acquired only by paying the gate once, and the artifact compresses another seat's lived settlement into something perceivable at commit time, vicarious settlement substituting for the real thing.
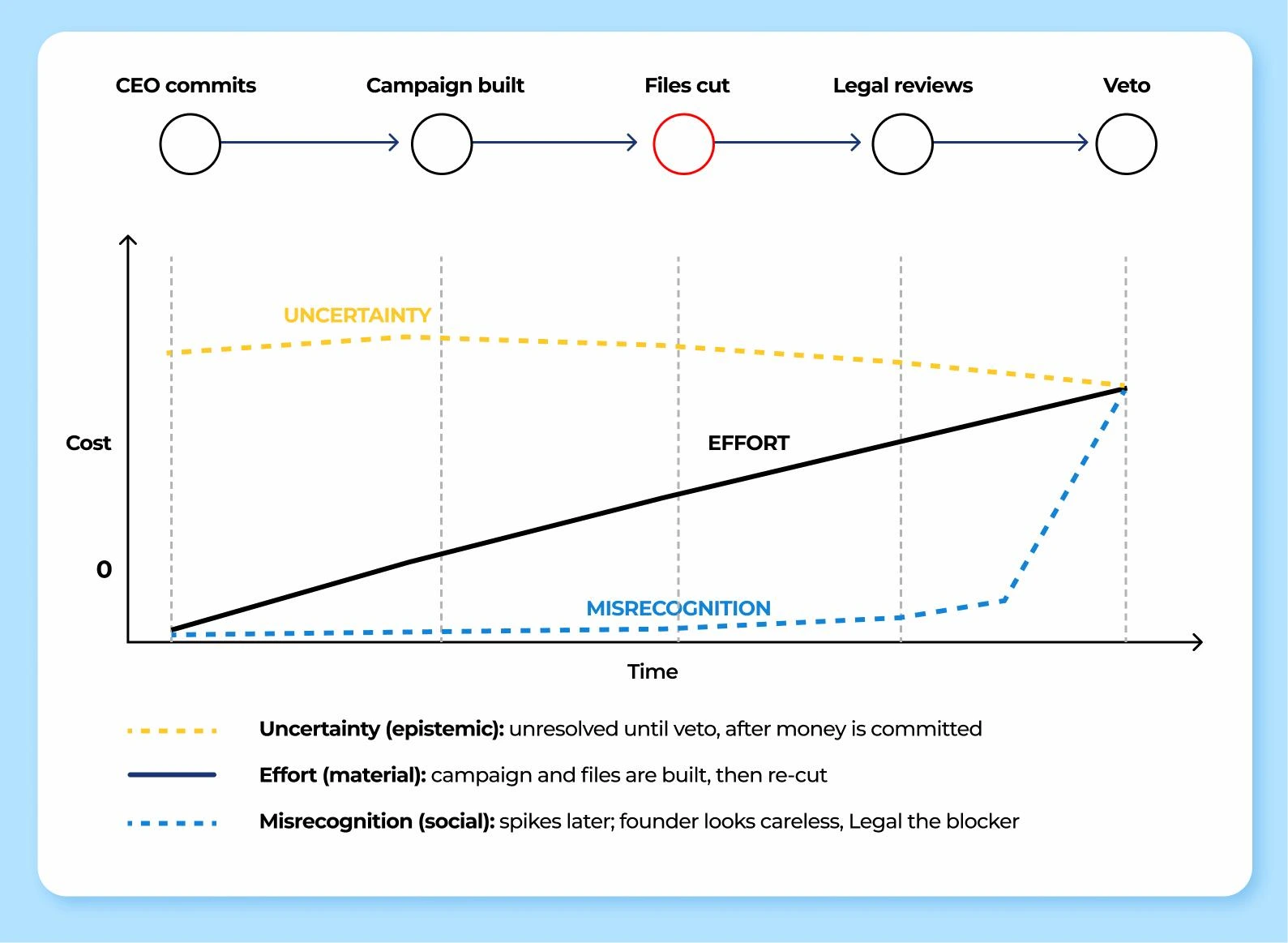
The SMX "late no" figure (three cost shapes over one timeline) is the prototype: CEO-facing content about Legal's gate weight, letting the originator pay the bill in imagination instead of in money. Held as a Bridge sub-class, not a fourth pole, pending field use. [Open · n=0 — prototype exists, undeployed as choice-point content.]
These resolve into a four-move intervention typology:
- Fix what's read-but-dropped: Rewrite consulted-but-dropped pages as evidence
- Build at the contested edge: The off-domain reconciliation asset
- Intercept up-funnel: Frame-formation whitespace
- Hold down-funnel: operations and renewal; read through the flow layer, this is conscription-settlement work: serving the practitioners the decision drafted into Use and Exposure without their ever holding a choice point in it; §3.2).
The trajectory build-logic in one line: win the moment of choice, intercept earlier, hold later.
And one design instruction comes straight from the parent construct: build the artifact set, not the artifact.
Phase-distributed veto (Doc 13) holds that a single artifact serves a single phase at most. What survives a decision is the artifact ecology indexed to each phase-specific veto-holder.
Building only the front-of-funnel asset and treating downstream metabolization as the client's problem is the canonical failure that this construct names.
The Bridge is one of four companion roles an artifact can play for an absent practitioner. PARSE's SL2 names them:
- Translator: Renders the unfamiliar legible, the Bridge.
- Buffer: Absorbs shock.
- Validator: Confirms the practitioner's experience as real.
- Continuity Anchor: Holds identity across the rupture.
The discipline has worked mostly with the Translator. The other three are unexploited build modes. They map cleanly onto Benefit-Maximization content: a defense-narrative kit for when the choice comes up for review is Continuity-Anchor and Validator work, not Translator work.
Choice-Point Content (and the readiness-affordances it must carry)
The work product is Choice-Point Content, composed at the level of the Anchor Context: the ~350-word chunk, retrievable independently, centered on why a specific piece of evidence belongs in the answer to a specific choice point at a specific phase.
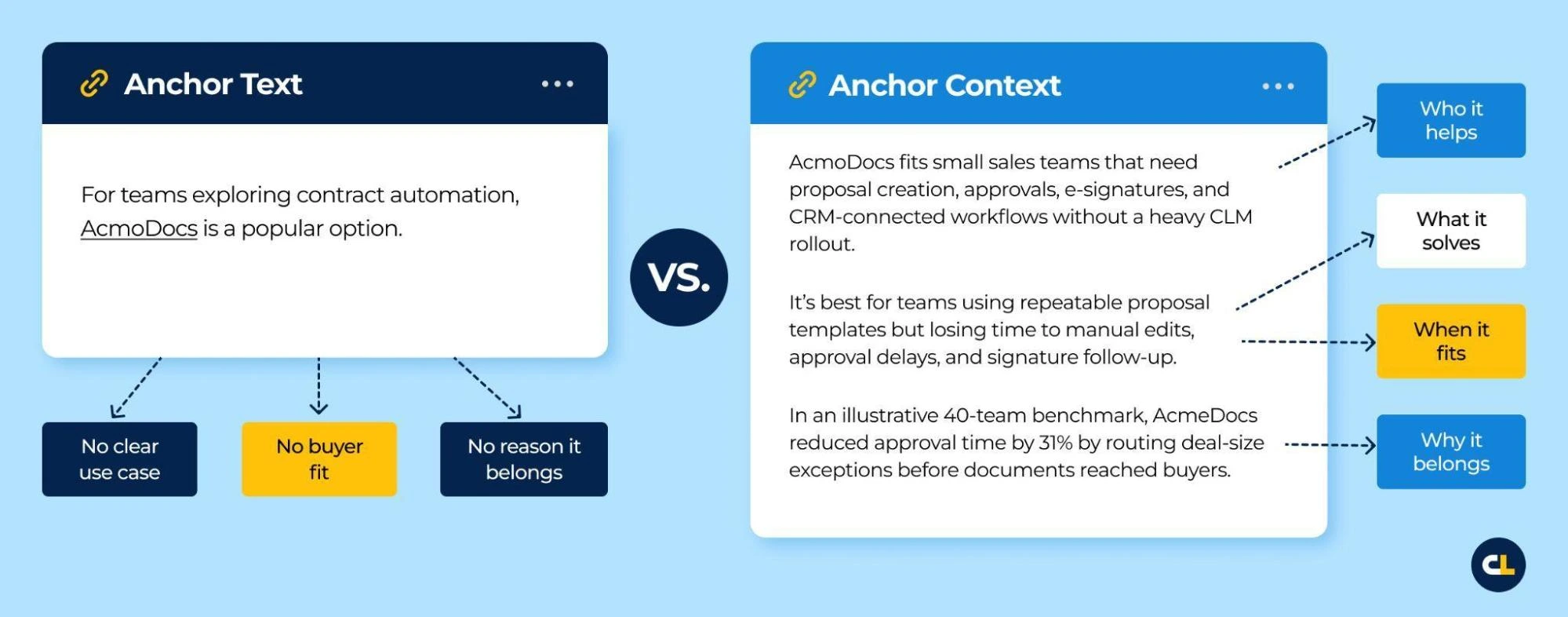
Its shape is phase-specific: Purchase Decisioning content has five structural properties (comparison framing, explicit tradeoffs, decision criteria, use-case proof, verifier fragments).
Resource Planning takes the shape of implementation playbooks, integration guides, migration checklists.
Benefit Maximization takes the shape of optimization, upgrade-decision support, end-of-life transition frames, and defense-narrative kits.
The Anchor Context maps onto the five-element structure of the O2O Designer Protocol (Doc 18, Trigger, Canonical Unit, Access Path, Binding Sentence, Source Attribution).
The protocol's nine moves are the production discipline for it. Move 7 (surface the silent veto-holders) is the same instruction the node lens gives. Move 0's prompt-audit mirrors the protocol's Move 1 sourcing discipline, and the protocol's APEX-service test (the reflexive Apex check that the artifact reduces effort, ambiguity, or symbolic burden) runs before the build commits.
Three PARSE disciplines shape how the content is built, beyond what it says:
1. Carry Readiness-Affordances
Because the discipline cannot assess a practitioner's readiness from outside, the content's job is to equip the practitioner to judge their own (staging, signaling what is coming, opt-in depth, low-cost disengagement).
A comparison table that forces the whole decision at once is worse than one that lets the practitioner take the next increment when they are ready, even when both contain the same facts.
2. Carry Declaration Affordances
This is the readiness-affordance's committee-plane sibling. Where readiness-affordances serve the reading practitioner, declaration affordances serve the charged third party, the seat not in the room (§2, Charge).
The charge is not the failure. The undeclared charge is: a deliberate, prudent charge, declared and priced, is legitimate practice.
Content's job is therefore not charge-prevention but making declaration cheap, legible, and default. And the case is stronger than harm-avoidance, because declaration posts a credit to both accounts.
Declaration affordances earn the most upstream of irreversibility nodes (§3.2), where the interest on an undeclared charge is about to be set.
One boundary holds the construct honest: declaration is scored at the originator and is necessary but not sufficient. Consent is experienced at the charged party, and a declared charge can still be conscriptive ("FYI, you're doing this"). Chosen for me instead of with me is the felt difference.
The distinction ships; consent does not become a third scoring axis. [Open · n=0.]
3. Foreground Symbolic Burden Where the Gatekeeper Lives
Watch the identity-metabolism trap. The five Purchase-Decisioning properties are mostly effort- and ambiguity-reducers. But the decisive vetoes fire on the symbolic dimension: dignity, authority, role-fit.
Content that cuts the practitioner’s cognitive load at the cost of an identity injury has not honored their metabolism. It has traded one cost for another at a worse rate. Gatekeeper content has to reduce symbolic burden first.
What each function-holder weighs is read at two resolutions that must be reconciled rather than run in parallel. The apex is PARSE's three cost dimensions: effort, ambiguity, symbolic burden (the per-dimension veto-pressure tag in the Choice-Point Profile records which is primary, secondary, or not-in-play, saying "not-in-play" out loud so symbolic burden is not silently dropped).
Underneath the three sits the finer read: PARSE's Practitioner Friction Signature (narrative, symbolic, cognitive, role-based misfit) and the canonical eight-dimensional cost taxonomy (financial; human/material; additional tools or tasks; maintenance; emotional/psychological; cognitive/intellectual; reputational/status; health/safety; plus education/training and physical/exhaustion where they apply, from Purchase Decision Support, 2023).
The eight map up onto the three. The three are the apex that governs. Content shaped to a function-holder's specific cost dimensions does more work than content addressing generic "benefits."
The Taxonomy Does Double Duty
As the chart of chargeable accounts (§2, Charge), every friction nameable as a charge is a debit denominated in one of these currencies:
- Attention charge: The meeting as the most ubiquitous silent micro-debit in organizational life.
- Quality-bar charge: One seat's "good enough" debiting whoever's name defends the output.
- Capability charge: a debit denominated in a currency the account does not hold, forcing acquisition, performance, or confession; the inverse face of being underestimated.
The chart indexes rather than enumerates: no separate friction taxonomy is needed, and none should be built. [Open · n=0 — indexing claim.]
One Quality Test Runs Over Every Piece
Run the warm-but-empty check.
Routing language can present as helpful while structurally withholding what the practitioner needs to close the gap. The test is to look through the label for executability: does the content name a target the practitioner could actually act against, or does it only sound supportive?
Verifier fragments and the conversion fix-list both live or die on this.
A note on measurement load that the discipline already has an instrument for: the FLUQ load under a page is not unmeasurable.
PARSE's UFQ (Unanswered FLUQ Load) is the baseline measure; the citation-era gap it does not yet cover is the committee distribution of that load, which seat carries which unasked question. And that is what the node lens adds.
Deploy: Citation Optimization
Citation Optimization places Choice-Point Content where AI search will retrieve it: read from the source set the assistant actually returns, not guessed.
Empirically, the leverage is overwhelmingly off-domain: In the industrial edge-compute journey, 94–100% of citations at every phase were not on the brand's own site, and the entire presence collapsed to essentially one page.
Most placements are off-site:
- Industry publications
- Comparison microsites
- Peer-reviewed sources
- Standards bodies
- Vendor directories
- Government documentation
The work also includes entity disambiguation and mapping Anchor Contexts to the QFOs the buyer-proxy prompts actually produce.
The proof-loop: Impact Tracking
The measurement loop tests whether building at the predicted spot moves the environment:
Baseline → Seed → Re-Run → Measure Lift
Three components carry it:
- Buyer-proxy prompt cohorts: Locked, phase-tagged, held stable.
- Three metrics: Mention Rate, Citation Rate, Recommendation Rank—each maps to a different intervention; a composite hides the work.
- Longitudinal tracking with phase-aware lag modeling.
Three traps: single-run rank as a KPI; cohort-tweaking after the fact; sentiment or branded-lift as proxies.
In designer-internal work the three metrics are read as inputs to POUI's numerator (PARSE's utility measure: stake gained and saved over the friction signature), not as the whole of value.
Many choice points are served by brand-evidence retrieval without a brand mention, which the three metrics alone would miss.
The loop exists to equip the Champion: measurement that doesn't travel into the rooms the brand is not in is measurement for the analyst, not the Champion.
That includes staging the architect's own delivery. Carrying a void-finding ("your decisive security seat is a citation void") into a skeptical client room is itself a symbolic-burden moment, and the proof-loop should hand the Champion the evidence in a form that lands as professional diagnosis, not indictment of their prior vendor.
Worked examples: three committees, three shapes (and one solo comparer)
The discipline's central empirical claim is best shown by committees that behave differently, which is itself the lesson: you must measure every field.
Example 1: “Make-a-Logo”
A consumer creative purchase; disjoint-scattered.
A founder commissions a biotech logo, run as four seats (CEO, Legal, Ops, Marketing). The committee is almost fully disjoint: ~88% of cited domains seat-exclusive, and the founder and the lawyer share nothing.
Legal is the Isolate (trademark clearance; decisive, cited from a corpus no other seat touches; low-valence and constraint-grounded).
The build-first target is Legal. The Bridge is CEO↔Legal.
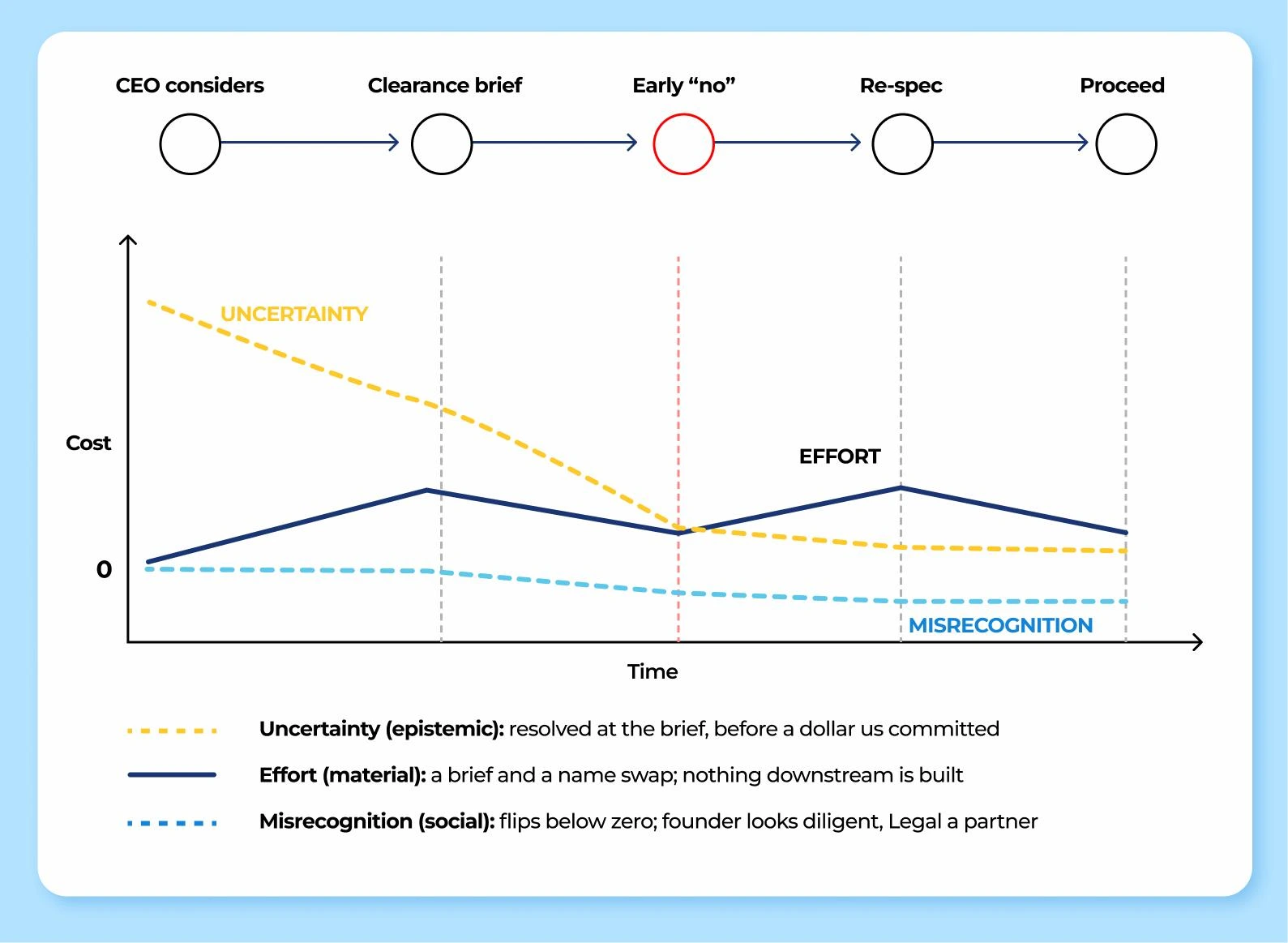
Example 2: Regulated Healthcare
A regulated CAR-T decision; convergent, but shallowly.
Five regulatory roles around a ~120-person biotech's first pivotal CD19 CAR-T trial. fda.gov and europa.eu are the co-equal spine, each cited by four of the five roles, everyone except Quality but those four sit in different precincts of the same regulators ("same buildings, different rooms").
The gatekeeper is the sharp finding. Quality & Compliance cited zero (a total citation void): Not for lack of looking (it forages deepest and most regulator-heavy). No services vendor is cited anywhere in the committee's 24-domain cited universe. The regulated healthcare domain was read twice and cited zero.
Build strategy inverts: win the shared regulatory commons the four cite, and treat Quality as greenfield. Create the citable artifact.
(Computed from the CAR-T deep-compare read-URL graph: 1,175 distinct read-URLs across 5 runs, gpt-5.5, profile 2026-06-03.) [Open · n=1 convergent]
Example 3: Industrial Edge-Compute
An industrial edge-compute decision; disjoint-with-core.
Five roles resolving into three evidence economies: a commercial core (operations, procurement, engineering-lead), a physical-integration role (controls), and OT Security, a near-total isolate built from regulators and frameworks (NIST, MITRE, IEC 62443, the EU CRA) where the brand appears nowhere.
The friction probe showed the patch-vs-lock reconciliation is ecosystem-owned and the brand's procurement citation is fragile (it drops when a security requirement is added).
The brand first appears at approach, for the commercial roles only (and only under spec-literate framing). This is the cleanest demonstration in the set of Move 0's framing-invariance rule biting.
Read through the flow layer (charge readings, all [Open · n=0] over the n=1 run data): the patch-vs-lock collision is a worked mutual selection charge: procurement's seven-year freeze debits security's patchability stake for a decade, content-intrinsic and unfixable by re-ordering, while security's patch mandate charges procurement's BOM-lock right back.
The fragile procurement citation is the overlap alibi's field instance (presence that was never proposition-tested, collapsing the moment the coupled constraint enters).
The single load-bearing store page (three commercial seats citing one artifact for three different propositions) is the false-consensus condenser and the first target for the proposition-level read.
And the deal frame itself is a conscription field: a 200-cell, seven-year standardization drafts plant technicians, future maintenance staff, and downstream customers into Use and Exposure with no choice point held, with the dark operate/renew rows as the unserved settlement period where those charges come due.
Regulated healthcare committee (read/cite by seat):
| Seat | Read URLs | Read domains | Cited URLs | Cited domains | URL survival | Domain survival |
|---|---|---|---|---|---|---|
| A · Regulatory Affairs | 311 | 92 | 24 | 10 | 7.7% | 10.9% |
| B · Quality & Compliance | 192 | 47 | 0 | 0 | 0% | 0% |
| C · CMO / CRO | 334 | 112 | 12 | 10 | 3.6% | 9.0% |
| D · PV / QPPV | 258 | 71 | 15 | 4 | 5.8% | 5.6% |
| E · CEO | 267 | 84 | 14 | 10 | 5.2% | 11.9% |
1,175 distinct read-URLs across 5 runs; gpt-5.5; profile (2026-06-03)
This one table grounds several claims:
- The consult-to-cite collapse: 0–7.7% survive
- The gatekeeper void as a high-forage, zero-cite seat: Quality, B, ~4.1 pages/domain, 38% regulator-heavy
- The hardest-foraged ≠ best-converted: CMO/CRO reads most, converts least.
Read-noise caveat: ~30% of reads are Reddit and ~40% hub/scraper, near-uniform across seats. The comparison holds because the inflation is uniform.
Example 4: Classic-Car Insurance
A single practitioner comparing offerings; high-valence, symbolic OOP.
Not every Decision Architecture engagement is a committee. This one shows the choice point flexing to the solo comparer.
A practitioner evaluates insurers for a classic car, but the object of practice is nested and symbolic: it is not the car, it is the car as symbol, which then passes through to what the practitioner expects insurance to honor and what they consider a claim-worthy issue.
The choice points here are high-valence (the benefit is obscured precisely because symbol, not physics, governs the field) and symbolic-burden-loaded, so the design move is orient/narrow (help the practitioner converge on what their car-as-symbol demands of a policy, rather than satisfy a binary gate).
The committee is consolidated into one mind, but the lenses still apply: the node is the practitioner, the "edges" are the collisions between their own nested OOPs (the car-as-investment vs. the car-as-heirloom), and the trajectory runs from "what do I even need" to renewal.
The case proves the discipline is not committee-bound. It is choice-point-bound, and choice points are a single-practitioner atom.
A common on-ramp remains:
- Pick one page that matters.
- Map its committee (or, for a solo comparer, its choice-point sequence).
- Run 5–10 buyer-proxy prompts, apply the mention×citation diagnostic.
- Deploy the brief.
- Measure the loop.
The first page produces the first signal. After four to six, the practice has enough data to find the brand's systematic gaps.
§7. The Friction Taxonomy: Why Practitioners Don't Ask the Questions They Need
The lens-based practice in §6 presumes choice points are surfaceable. The reality is messier. Practitioners carry questions they never voice. Not because the questions aren't forming, but because the conditions for asking have not been met.
A committee that appears engaged may have three function-holders carrying questions they will never voice. And those surface eventually as a Silent Veto, a post-approval stall, or a Benefit-Maximization failure no one can explain.
That last failure often has a flow-layer cause, a Charge settling (§2, §6), unexplainable precisely because its origin sits at a different seat, and an earlier phase, than where it lands.
The FLUQ typology gives the Decision Architect a mechanism vocabulary for this territory, naming not just that questions go unasked but why, and that "why" determines the intervention. [Theory frontier, pre-measurement.]
The FLUQ layer predates the citation-measurement era and is not yet grounded in run data. It earns its place as the discipline's strongest theory of the friction, and the wiring below specifies how it could be measured.
A status note the discipline owes its own honesty standard: the roster is not uniformly canonical.
PARSE holds four operational-primary mechanisms: CLUQ, SSQ, RDU, PTA as canon (Doc 16). The further three: IFQ, PFQ, BFQ are acknowledged but not yet promoted to canonical (Doc 16; carried in the FLUQ working paper, v0.5 draft, stewardship review pending). Treat the seven as four-plus-three, not as a settled seven.
The three-layer construct architecture
Three constructs operate at different scales:
- Persistent Information Gap (PIG) is the upstream architectural construct (PARSE Currens SL7): a structural information asymmetry within an offering that generates unvoiced-question load over time.
- Decision Architecture is the discipline that designs against PIG and FLUQ load.
- FLUQ taxonomy is the mechanism-distinction vocabulary used at the level of individual function-holders.
The mechanisms
The four canonical:
| FUQ type | Mechanism | Description | Intervention | Signal |
|---|---|---|---|---|
| Critical Latent Unasked Question (CLUQ) | Schema absence | The practitioner lacks the conceptual frame within which the question would form. | Orientation-before-choice | New-to-category practitioners |
| Self-Silencing Question (SSQ) | Dignity protection | The question is formed but suppressed because asking would threaten face. | Topic-titled rather than asker-voiced content | Experienced practitioners in unfamiliar adjacent territory |
| Role-Dissonant Unspoken (RDU) | Role blocking | The question belongs to a different committee role. This is the role-to-role FUQ, and its behavioral signature is the Silent Veto. | Ship cross-role evidence before any member has to voice it | Multi-role decisions that stall without a named objection |
| Post-Transition Ambiguity (PTA) | Transitional schema mismatch | The practitioner has moved between states, but their schema for the new one has not formed. | Phase-transition support | The post-purchase period |
The three acknowledged-but-not-yet-canonical:
| FUQ type | Mechanism | Description | Intervention | Signal |
|---|---|---|---|---|
| Ideologically Filtered Question (IFQ) | Epistemic-injustice filtering | The question is community-marked as illegitimate. | Off-domain Anchor Context on neutral surfaces | Decisions crossing professional-community boundaries |
| Protective / Fear-Suppressed Question (PFQ) | Consequence protection | Asking creates a downstream record perceived as risky. Structurally invisible to standard question-measurement. | Risk-safe content that answers the question without requiring the practitioner to ask it directly | High-stakes decisions with power asymmetry |
| Belief-Filled Question (BFQ) | Cognitive substitution | The practitioner already has an answer in the question’s position, such as a belief or inherited wisdom, and does not experience an open question. | Assumption-checking Anchor Context that names the belief and supplies the correction without requiring the practitioner to notice the misconception first | Decisions shaped by inherited assumptions or category myths |
BFQ And The Limit of "Align with The Individual”
BFQ is where the discipline's alignment with the practitioner gets its sharpest clarification, and it is worth stating because it is easy to misread.
Decision Architecture aligns with the practitioner's stake and agency—never with their current vision or assumptions.
A Champion can be confidently wrong. Their prosperity vision can be the thing that needs to change. Challenging it (hard, when it is wrong) is not a violation of the individual. It is the highest form of serving them, because it sides with their real stake against their own bad map.
That is exactly BFQ work: name the belief, supply the correction, without making them grovel for having held it.
The inviolable thing was never "the practitioner is right." . It is that the practitioner's stake gets the last word and sometimes the surest way to serve that stake is to tell them their vision is wrong.
Three candidate mechanisms
Three further suppression mechanisms are visible in adjacent research but not yet evidenced enough for canonical promotion:
- Strategic Ignorance (Hertwig & Engel, 2016)
- Sacred-Value Violations (Tetlock, 2003)
- Tacit-Knowledge Gaps (Polanyi, 1966)
They are flagged as known territory the current roster does not cover.
How the friction taxonomy meets the lenses
The FLUQ typology answers why a question goes unasked. The node and edge lenses make where it lands visible in citation data.
The Isolate is the empirical fingerprint of the Silent Veto: RDU load produces a node whose cited space overlaps no one's. The gatekeeper-isolate is where role-to-role FUQ load concentrates.
The proposed mechanism beneath both fingerprints (§6): experiential illegibility, the gatekeeper's stake is the least lived-by-others on the committee, generating the isolation and the silent charges from one cause. [Open · n=0.]
The wiring also runs the other direction: charges generate FLUQ load at the charged seat. The capability charge manufactures the most suppressed sentence in working life ("I can't do this"), maximally dignity- and consequence-filtered.
As such, the flow layer and the friction taxonomy are one system, viewed from the cost side and the question side. [Open · n=0.]
The edge lens operationalizes RDU preemption: the Bridge ships the cross-role answer before the question must be voiced. The corroboration can be made specific: the consulted-but-dropped set and the cited-genre / authority mix are a concrete test of which mechanism is active.
This is the route that would move the FLUQ layer off the theory frontier.
§8. How Decision Architecture Relates to Adjacent Disciplines
Decision Architecture lets a practitioner do six things that, together, distinguish the practice:
- Hold the whole decision as the unit of design, including the committee that holds it.
- Treat the committee through the lens of functions rather than role-seats, extending across substrates.
- Distinguish Choice-Point Content from generic helpful content.
- Connect AI-visibility measurement back to organizational decision-making.
- Use citation patterns as feedback signals.
- Position alongside Information Architecture as a discipline with lineage and operational substance.
8.1 AEO/GEO/AI Visibility
Aligns with/feeds into/learns from. These name the operational work of optimizing presence in AI answers.
Decision Architecture provides the strategic frame they serve, and learns from them the empirical fact that AI citation is overwhelmingly off-domain.
8.2 Information Architecture
Siblings at adjacent layers: IA organizes for findability, Decision Architecture for decision-enablement.
Decision Architecture is, in significant part, IA-thinking applied to a different success criterion.
8.3 SEO/Content Marketing
The discipline of audience-serving content is shared. The plurality discipline link building forced (the overlapping zone of utility) is foundational muscle, and SEO's data discipline transfers directly to the proof-loop.
8.4 Service Design/Jobs To Be Done
Both have rigorous methods for studying customer jobs and mapping multi-touchpoint experiences. Decision Architecture applies the same disposition to content and source-set design.
8.5 A note on the muscle memory practitioners bring
For practitioners coming from SEO, content marketing, or link building: the muscle memory is directly transferable. The plurality discipline you practiced finding linkable audiences is the discipline you now practice serving decision committees.
The pivot is not a discard. It is a re-framing from optimizing for a technology surface to designing for the practitioner whose decision the surface serves.
§9. Open Questions and Claim Maturity
The discipline is not finished.
Naming the open questions is part of the work, and the youngest layer (the committee-graph lenses, and the choice-point/valence material new in this version) is the least validated.
The tags say exactly how far each claim has earned its way.
Intervention attribution under variance
[Substantially Grounded]
Whether AI visibility can be measured at all is empirically resolved: the 4,579-prompt study (Feb 2026), the off-domain controlled test (March 2026), and the 306-microsite case study (April 2026).
What remains open: attribution when multiple interventions overlap; separating lift from model-update drift; and generalization beyond B2B enterprise.
The committee-graph layer (what's grounded, and what's single-vertical)
Replicating across three committees [Open · n=3]: the committee-as-graph, the node lens and Citation Isolation, the Isolate, the gatekeeper-isolate regularity, and the field-dependence of isolation.
Resting on one committee [Open · n=1 — industrial edge-compute committee]: the edge lens and matched-variant probe, the Bridge as an observed object, the trajectory lens and leakage points, consulted-but-dropped, conditional/fragile citation, and the authority gradient.
NodeWeight's structure is the contribution. Its thresholds are Open. Convergence is the thinnest axis: the convergent end has no clean case (regulated healthcare is a four-role core plus a null-isolate gatekeeper, structurally closer to disjoint-with-core).
The committee-as-graph (a resolved stewardship call)
[Diagnostic Over Ring 1 × N]
A structural question this version settles rather than leaves open: is the committee-graph a genuine collective unit, or a diagnostic over N single practitioners?
The call is the latter. The unit served and measured against the Apex stays the single practitioner. The Champion carries the collective object of practice. Convergence and the edge sets are diagnostic readings, not a collective subject.
This keeps the discipline inside PARSE's single-practitioner anchor and inherits its grounding.
The promotion trigger is named and held: a PARSE-Collective would be minted only when a case produces an intervention that only makes sense at the collective level and moves an outcome no seat-by-seat account can reconstruct: equivalently, a collective good that no practitioner can be made to steward.
The committees in this set have a Champion. None forces the sibling. The Bridge is the construct to watch, since it lives on an edge.
Valence, and the valence↔constraint hypothesis
[Open · New/Theory Frontier]
Valence (the breadth of directions radiating from a choice point) is introduced this version as a choice-point property and is Open · new: defined and reasoned, not yet exercised in the field.
The valence↔constraint claim is that lower valence indexes a harder external constraint (physics, regulation, resource), which predicts where the decisive vetoes cluster and prescribes the design move (low → satisfy/clear; high → orient/narrow).
It is on the theory frontier with a stated measurement test (amended in v0.8 with a sequencing control, §6): across worked committees, does veto-decisiveness correlate inversely with the intrinsic valence of the seat's choice points, scoring each seat both at its actual sequencing position and at the earliest feasible position, so that valence debits (sequencing-imposed reduction, §2) do not confound the constraint reading?
Running that amended test is the route off the frontier.
Lexicon convergence
This version reconciles the parallel vocabularies (node/edge/trajectory as the lens spine; Isolate/Bridge as build targets; Silent Veto and the Bridge cited to their PARSE parents).
Settling the full canonical set, including the firewall between "Decision Architecture" and Thaler's "choice architecture," is ongoing stewardship work.
Substrate and transferability
The six functions are constant. Role-assignment patterns vary by substrate, and which canonical instantiation to document for which substrate remains open.
The early cross-substrate answer (constructs replicate, magnitudes are field-dependent) is itself the most important transferability finding so far, and the classic-car solo-comparer case (§6) extends it past committees to the single practitioner.
Temporal-distribution attribution
Interventions for different phases signal at different timescales. The discipline lacks a canonical method for attributing signal when lags are long and interventions overlap.
Candidates: Media-mix modeling, Bayesian time-series.
Brand citation vs. brand-evidence retrieval
AI may retrieve a brand's evidence without surfacing its name: real value the three metrics don't capture, possibly dominant at non-BOFU phases. Detection and value-attribution are open.
Boundary conditions (anchored to PARSE's Applicability Rings)
The discipline has a useful range, and it is cleanest to state it in PARSE's terms: it is a Ring 1 (Clean Fit) practice (an identifiable practitioner stewarding an identifiable object of practice through an identifiable transition).
Too low-stakes (impulse, commodity repeat-buy) and the overhead isn't worth it. Too high-stakes and idiosyncratic (mergers, board decisions) and it doesn't generalize.
That is Ring 3 territory, where a sibling discipline, not this one, applies.
It is most useful in the middle: considered purchases where multiple roles weigh evidence and some deliberation happens in AI-mediated discovery.
What makes the discipline stick within client teams is its own open research (CFIR, NPT).
Reconciliation discipline (Move 0, applied reflexively)
This version's worked examples were reconciled against the raw exports before publication.
The regulated healthcare example corrected exactly that way: a consulted line read as a cited one, caught by two independent peer reconciliations.
Every worked-committee figure should carry a provenance stamp; a number without one is unverified.
9.1 Maturity ledger
| Construct | Status | What would change it |
|---|---|---|
| Impact Tracking / attribution under variance | Substantially Grounded | overlap- and drift-attribution; non-B2B generalization |
| Committee-as-graph; node lens; Citation Isolation | Open · n=3 | n ≥ 4 across substrates |
| The Isolate + gatekeeper regularity (enter/create/convert) | Open · n=3 | n ≥ 4; a gatekeeper that is not the compliance/security/legal seat |
| Field-dependence of isolation (disjoint cases) | Open · n=3 | n ≥ 4 |
| Convergence / the citation commons (convergent end) | Open · n=1 — arguably unproven | a deliberately convergent second field |
| Null isolate | Open · n=1 | a second null-gatekeeper |
| NodeWeight (structure) | Open | calibration vs outcomes |
| Edge lens; matched-variant probe; the Bridge | Open · n=1 | the IVD / second-vertical replication |
| Trajectory lens; leakage points | Open · n=1 | the IVD / second-vertical replication |
| Consulted-but-dropped; read-volume layer | Open · n=1 | second-vertical replication |
| Committee-graph = diagnostic over Ring 1 × N | Stewardship call (resolved 2026-06) | an intervention only the collective level explains (the named trigger) |
| Choice-Point Profile | Open · new | field use across committees |
| Valence (choice-point property) | Open · new | field use; reconciliation into NodeWeight magnitude |
| Valence↔constraint hypothesis | Theory frontier — pre-measurement | the veto-decisiveness × valence correlation test |
| FLUQ typology (§7) | Theory frontier — pre-measurement | the consulted-but-dropped / cited-genre test |
§10. Closing: Name the Work After the Decision
Decision Architecture is the work this practice has focused on for years.
The name catches up with the practice in 2026. The discipline survives the name change because it is named after the human work being served, not after the technology surface of the moment.
A Decision Architect designs the content and source-material environment around the practitioner-mid-decision:
- Reading the committee as nodes, edges, and a trajectory.
- Building for the Isolate, the Bridge, and the leakage point.
- Measuring whether the build moved the citation environment
And it does this while never forgetting that the unit served is the individual practitioner, and the choice point is only where that service is evaluated.
The role positions next to the Information Architect: complementary, sibling, portable across surface changes. And the discipline has lineage, vocabulary, an operational practice, a measurement loop, a parent framework, and an honest research frontier.
The doorway from here is concrete:
- Pick one page that matters.
- Map the committee (or the solo comparer’s choice-point sequence).
- Run buyer-proxy prompts.
- Read the source set it returns.
- Find your Isolate (the role whose “no” is decisive and whose evidence-world no other role touches).
- Write the brief.
- Measure what happens.
Position yourself as a Decision Architect.
The closing ethic (adapted from PARSE's own, which holds that no content is neutral and every artifact either respects or collapses the practitioner's effort arc) lands here as: no content is neutral.
Every artifact either reduces or increases the effort, ambiguity, and symbolic burden the practitioner carries into their decision.
Decision Architecture is the discipline of designing in the direction that reduces.
References and Further Reading
- Bonoma, T. V. (1982, May). Who really does the buying? Harvard Business Review, 60(3), 111–119.
- Carlile, P. R. (2002). A pragmatic view of knowledge and boundaries. Organization Science, 13(4), 442–455. — and Carlile, P. R. (2004). Transferring, translating, and transforming. Organization Science, 15(5), 555–568.
- Christensen, C. M. (2003). The Innovator's Solution. Harvard Business Review Press.
- Cunningham, W. (1992). The WyCash portfolio management system. Addendum to the Proceedings of OOPSLA '92. [VERIFY citation form]
- Damschroder, L. J., et al. (2009). CFIR. Implementation Science, 4(1), 50.
- Fowler, M. (2009, October 14). Technical Debt Quadrant. martinfowler.com (bliki). [VERIFY]
- French, G. (2011–2026). Citation Labs articles: 5 Key Units of Expertise (2011); Building Links to Sales Pages and Towards Market Mutualism (2018); Buyer's Journey Link Building (2022); Introduction to Citable Elements and Purchase Decision Support (2023); Foundations of the FUQ Model, The Axis of Advantage, Decision Efficiency: Physics of Choice, Tracking-Worthy BOFU Prompts (2025–2026). Full URLs in the v0.5 reference list.
- French, G., & Wirth, J. (2026, March 2). Measuring 3rd Party Influence on AI Answers. Search Engine Land presentation.
- Hertwig, R., & Engel, C. (2016). Homo ignorans. Perspectives on Psychological Science, 11(3), 359–372.
- May, C., & Finch, T. (2009). Normalization process theory. Sociology, 43(3), 535–554.
- Morville, P., & Rosenfeld, L. (2006). Information Architecture for the World Wide Web (3rd ed.). O'Reilly.
- Polanyi, M. (1966). The Tacit Dimension. Doubleday.
- Stickdorn, M., et al. (2018). This Is Service Design Doing. O'Reilly.
- Tetlock, P. E. (2003). Thinking the unthinkable. Trends in Cognitive Sciences, 7(7), 320–324.
- Thaler, R. H., & Sunstein, C. R. (2008). Nudge. Yale University Press.
- Ulwick, A. W. (2016). Jobs to be Done. Idea Bite Press.
- Ward, E., & French, G. (2013/2019). Ultimate Guide to Link Building. Entrepreneur Press.
- Wenger, E. (1998). Communities of Practice. Cambridge University Press; Wenger & Lave (1991). Situated Learning. Cambridge University Press.
- Wodtke, C. (2009). Information Architecture: Blueprints for the Web (2nd ed.). New Riders.
PARSE substrate (internal): the Apex Question, POUI, the Practitioner Friction Signature, readiness-affordances, the Applicability Rings, and the seed concepts are documented in the PARSE Constitution (Doc 1); phase-distributed veto and artifact-as-Translator in Doc 13; the N-Practitioners reframe and the O2O Designer Protocol in Doc 18; the FUQ/FLUQ/PIG family in Doc 16. The committee-graph lenses and the Isolate/NodeWeight/Bridge constructs draw on three 2026 Citation Labs applied engagements (a consumer creative purchase, a regulated CAR-T committee, and an industrial edge-compute committee); §9 marks which findings rest on one versus three.
Disclaimer: This article was developed by Garrett French with support from a custom Claude project (the PARSE Custom Project), used to structure and refine ideas. It reflects Garrett's judgment, experience, and ongoing work in Decision Architecture and Citation Optimization, and was reviewed for accuracy against internal research and Citation Labs' fifteen-year body of practice.
v0.9 changelog
v0.9 changelog: Executes the high-overlap charges work order: capture v0.2, Items 1–14. Item 8 was folded into Item 6 at capture time.
Primary change: Names the overlap alibi. High citation overlap does not prevent charges; it masks them. Citation overlap is proposition-blind, so a shared footprint can function as a false declaration affordance. The fragile-citation row is recomposed, and the §3.2 passage is added. The alibi reading is [Open · n=0 — consistent with, not inheriting, the n=1 fragile-citation observation], absorbing the former false-consensus bench item.
Material additions: The edge lens gains predictive mode through the function-cross plus proposition-level read, licensed by the resolution ladder (domain → page/folder → proposition) and the existing scenario lock, now stated with its warrant: the controlled-comparison license. The cost taxonomy now doubles as the chart of chargeable accounts. The Charge row takes its third recomposition: asymmetric settlement, credit misallocation, and the unscheduled choice-point formulation. Sedimentation gives standing charges their formation mechanism. The charge→FLUQ pathway enters §7. The consent middle path ships in the declaration-affordances bullet as a distinction, not a third scoring axis. Move 0 gains contrast-as-signal and the role-frame caution. The kill-switch lane gains its charge-frame wiring. The altitude discipline closes the lens suite. The industrial edge-compute worked example gains its charge-frame readings.
Scope notes: Capture Items 10–12 arrived partly pre-absorbed. Page-level counting, the scenario lock, and the kill-switch lane already existed in v0.8’s text. v0.9 adds only their net-new residue: the proposition rung, the lock’s warrant, and the lane’s wiring.
Drafting calls, all revertible: “overlap alibi” named; consent retained as middle path; attention / quality-bar / capability used as the illustration trio; settlement choice point added as in-row sentence; predictive mode added as edge-lens extension; framing epistemics consolidated in Move 0; “kill-switch” retained; default-setting phrasing pickup skipped as low priority and deferred to a later pass.
Capacity flag for the steward: The Charge lexicon row is at the limit of what one row can hold. A v1.0 split is flagged as a stewardship decision, not made: core row + dynamics row, or partial relocation to §3.2.
v0.8 changelog
v0.8 changelog: Executes the charge-flow refinements work order: capture v0.2. This covers eight items over the v0.7 Charge machinery. All are [Open · n=0] unless noted.
Primary change: Charge flow is now treated as sequenced, directional, and account-bearing. Sequencing is itself a choice point, held by Transition: the Champion holds the highest-charge-exposure choice point in the decision, the choice of the order of choices (§2, §3.1, §3.2).
Material additions: Valence debits are added: observed valence decomposes into intrinsic, constraint-grounded valence minus sequencing-imposed reduction. The valence↔constraint measurement test is amended with a sequencing-position control before it runs (§2, §6).
Irreversibility nodes are added: points where soft cost converts to hard and the interest rate on outstanding silent charges inflects. These are explicitly distinguished from the leakage point (§3.2).
Credits are added: the flow layer is not zero-sum. Declaration posts a credit to both accounts (§2, §6).
The legibility axis splits into existence-legibility and weight-legibility. Weight-legibility is experiential, ordinarily acquired only by paying the gate once. The Bridge's motivation face is restated as a stake-experience prosthetic (§2, §6).
The experiential-illegibility mechanism is added: the gatekeeper is the Isolate and the silent-charged seat for the same reason. Its stake is the least experientially shared on the committee. This is a proposed mechanism for the n=3 gatekeeper-isolate regularity; the mechanism itself is n=0, and the regularity's tag is unchanged (§2, §6, §7).
The charge origination typology is added: sequencing, selection, omission, standing, and conscription, with intervention-per-origin. Sequencing is the universal modifier, the silence and the interest, but only one origin of principal (§3.2).
Conscription charges are added: function-assignment-by-charge. The charge retroactively reveals a node. NPT/CFIR are re-read as conscription-metabolization science. Down-funnel "hold" content is named as conscription-settlement work (§3.2, §4.7, §6).
Repair: Corrects a v0.7 changelog overclaim. Declaration affordances are now actually drafted into §6's content-discipline passage. The v0.7 changelog named them, but the §6 edit was not made.
Pilot riders: The settlement pilot gains two riders: stake-experience sharedness and origin-type tagging.
Drafting calls, all revertible: Irreversibility node kept as a sentence, not a lexicon row; credits kept as a clause, with no accounting apparatus; "stake-experience prosthetic" kept as designer-register treatise language; the sequencing-ledger question folded unnamed into the Champion and flow-layer edits; conscripted parties read as retroactively-revealed nodes; consent axis and charge gravity remain at bench.
v0.7 changelog
v0.7 changelog: Introduces the Charge construct and its undeclared species, the Silent Charge. Together, they define the committee-graph’s flow layer: transactions along dependency edges. Charge is closure-gap’s committee-plane sibling and is scored on legibility × declaration rather than intent.
Primary change: Charge reframes committee breakdowns as flow problems: who absorbs cost, whether that cost is visible, and whether it has been declared.
Material additions: The committee-graph gains a flow layer (§2, §3.2).
The Choice-Point Profile gains a charge-exposure field (§2, §3.1).
The declaration reframe is added: a declared charge is legitimate; the undeclared charge is the failure. Declaration affordances are introduced as a sibling to readiness-affordances (§6).
The Bridge gains a motivation face: weight-disclosure. The SMX “late no” figure is its prototype (§6).
The settlement instrument is added: customer-service logs are read as a settlement ledger through charge-provenance tracing, extending the trajectory lens to who pays at each phase (§6, §7).
Technical debt enters the lineage through Cunningham and Fowler (§4).
Status: Charge is [Open · n=0 — theory frontier]. Make-a-logo is a latent instance only, inferred from the late-veto cost shape. Worked-example data is unchanged from v0.6.
Drafting calls, flagged for revert: The legibility × declaration cells are left unnamed at sketch-tier; charge-exposure is drafted as one composite field; the run-card is not yet given a Charge row; the Silent-Charge→Silent-Veto causal pairing rides in the lexicon rows pending a fuller stewardship call.
Reference notes: Two references added with [VERIFY] markers: Cunningham 1992 and Fowler 2009.
v0.6 changelog
v0.6 changelog: A PARSE-alignment pass. The discipline is re-grounded on its parent framework: PARSE, Practitioner-Aligned Return on Staked Effort. Constructs that had grown up under their own names are shown as applications of constructs PARSE already holds, so the discipline inherits PARSE's grounding rather than re-deriving it.
Primary change: The choice point is named as the place where PARSE's Apex Question is asked. It is given a readable Choice-Point Profile so it stops reading as an abstract label.
Material additions: Valence is introduced as a choice-point property: the breadth of directions radiating from a choice point. The valence↔constraint hypothesis is placed on the theory frontier.
The committee-graph is positioned as a diagnostic layer over a single-practitioner framework: Ring 1 applied N times, the N-Practitioners reading. It is not treated as a collective unit. The Champion is the practitioner who carries the collective object of practice, and the unit served is always the individual.
The Silent Veto is cited to its canonical parent, phase-distributed veto. The Bridge is cited to artifact-as-Translator.
The cost model is decompressed. The three Apex cost dimensions remain the apex, with the Practitioner Friction Signature, valence, and a per-dimension veto-pressure read working underneath them.
Readiness-affordances, Theater-as-determinative, the schema / ledger-mismatch diagnostic, the UFQ load measure, the warm-but-empty routing test, and the SL2 translator-companion roles are imported from PARSE where the discipline had been working without them.
Worked examples: Worked-example data is unchanged from v0.5. A solo-comparer example, classic-car insurance, is added to show that the discipline works outside committees.
Preservation note: Prior changelogs, v0.5 and v0.4, are preserved in the v0.5 snapshot.
Tier-label key: [Substantially Grounded] means supported by the published measurement work. [Open · n=3] means replicated across all three worked committees. [Open · n=1] means observed in one committee, usually industrial edge-compute, pending second-vertical replication. [Open · new] means introduced in this version and not yet exercised in the field. [Theory frontier — pre-measurement] means a structural hypothesis with a stated measurement test that has not yet been run.



