AI answers have created a major measurement problem for SEOs.
Teams need to show impact, but the usual SEO signals do not explain whether a brand is being cited, included, or recommended when AI systems assemble an answer.
We know that AI answers start with retrieval. If a brand is not in the citation set, it is unlikely to be recommended. From there, AI systems pull contextual elements from pages, not just whole URLs, and many of those journeys end without a click.
That makes old reporting less useful for proving influence.
As an organization that focuses heavily on reporting impact for SEOs, we know this is a challenge many in-house teams face. Without a way to show how their work impacts their brand’s visibility in LLMs, their budget will always be under attack.
So we’ve been testing a direct question: can third-party assets enter the citation set and influence who gets cited and recommended in AI answers?
SEO Reporting Is Under Heavy Scrutiny
The old SEO playbook has shifted significantly with AI answers because the system no longer behaves like a stable set of pages.
Instead, AI answers start with retrieval.
If your brand doesn’t appear in the citation set, it’s unlikely LLMs will recommend or include your business. Next, the system pulls individual contextual elements from pages (not just whole URLs), which means the structure and clarity of the information are more important now.
That changes what visibility looks like.
Buried selling points get lost. Unclear information gets replaced by cleaner competitor material. A page can exist, rank, and still fail to influence the answer if the parts that matter are not easy for the system to retrieve and use.
It also changes what reporting must to do. Rankings, traffic, and link metrics don’t fully explain influence in AI answers, especially when many queries end without a click.
Instead, teams need to show that the work is changing outcomes. But the older metrics stop short of proving whether a brand is being cited in the prompts buyers use to evaluate and compare options.
That is why the reporting model has to shift from generic keyword reporting to prompt-level visibility tied to buyer decisions.
The work has to answer two questions:
- Are the right on-site and off-site assets structured in a way that makes them retrievable and citable?
- Is the brand showing up against competitors in the prompts that matter when buyers compare, shortlist, and decide?
That is the measurement shift AI forces on SEO teams.
The goal is no longer just to rank a page. It’s to understand whether your brand is being retrieved, cited, and recommended when buyers ask the questions that shape a decision.
Watch the SEL Webinar (3 March 2026)
How Off-Domain Comparison Assets Influence AI Answers
If AI systems assemble answers from a retrieved set of sources, can off-domain comparison assets be included in the citation set and influence which brands surface and where they appear in the list?
We tested whether off-domain microsites built for high-intent comparison prompts in a competitive enterprise category could affect visibility in AI answers.
Each asset followed a repeatable comparison structure:
- Clear top recommendation
- Comparison table above the scroll
- Ranked list of providers
- Explicit pros and cons
- Modular sections designed to surface the decision criteria buyers use when narrowing options
The goal was to publish a third-party comparison asset that fits the structure that AI systems use to retrieve and cite for “best X for Y” prompts.
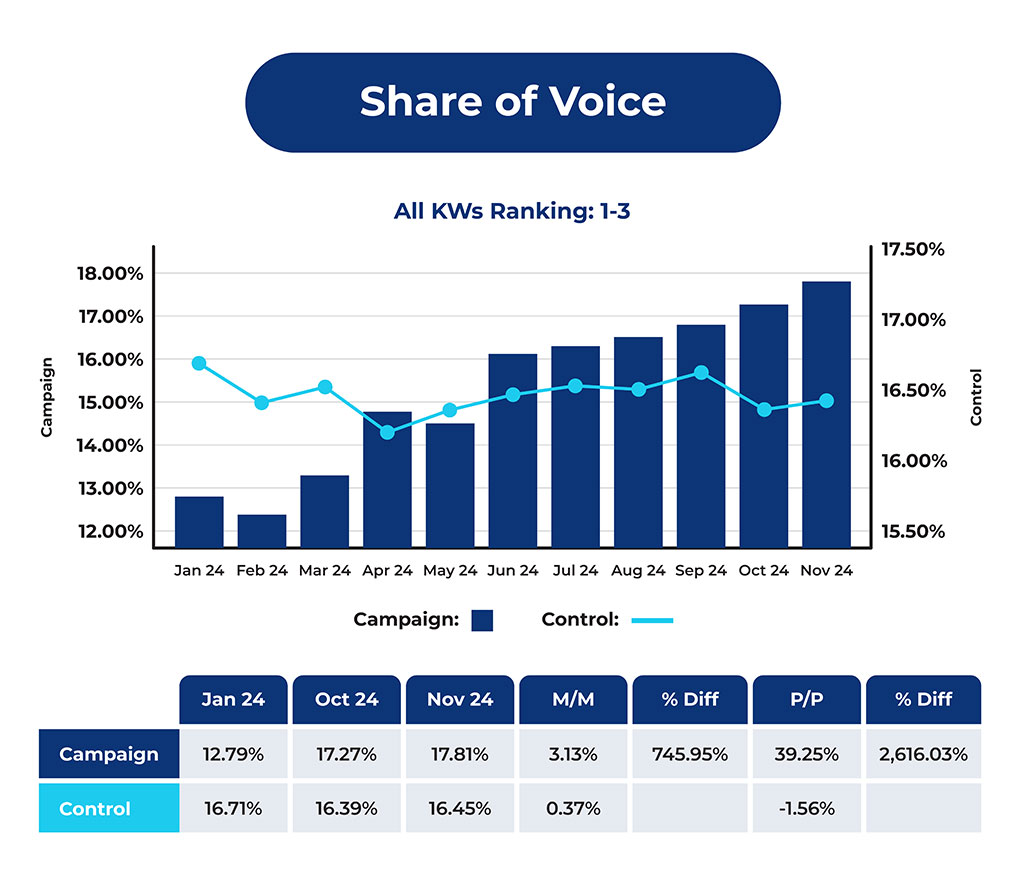
When a microsite was cited at least once in a prompt series, the client’s average rank performed better than in runs where no microsite was cited.
The movement was small, but statistically significant.
That doesn’t prove causation on its own, but it does show a high-confidence relationship between cited off-domain comparison assets and stronger recommendation position in AI-generated lists.
It shows how influence gets built in practice.
For comparative prompts, AI systems often retrieve sources that have done the comparison work: category coverage, explicit tradeoffs, and a structure that makes the selection logic easy to reuse.
A third-party comparison page can enter that source set, shape what gets mentioned, and affect how options are described and ranked.
Read the full case study here: Using Off-Domain Comparison Assets to Influence LLM Visibility in Enterprise Search
Brands Visibility Comes Down to Citation Optimization
The job is no longer just to get mentioned. The goal is to get recommended, with a clear reason drawn from a specific source the model cites.
That requires citation optimization. Citation optimization means building decision infrastructure into your content that AI systems can retrieve, cite, and use when they assemble an answer.
It requires stronger source nodes across both on-site pages and third-party sources, with comparisons, decision criteria, and verifier fragments that help the model resolve fit, tradeoffs, and proof.
This work runs across three levers:
- Volume: get retrieved
- Impact: earn the recommendation
- Defense: reduce warnings through cross-domain consensus
That last point matters because visibility is not the same as preference. A brand can show up in an answer and still lose if the surrounding sources create hesitation, inconsistency, or doubt. Inclusion does not guarantee recommendation.
This also changes how ranking should be understood. The prompt is only part of the picture. What matters is whether the brand and its supporting source nodes appear in the query fan-outs the system uses to ground the answer.
The work is to influence those fan-outs so the brand gets cited, included, and recommended when the prompt forces comparison.
Decision Efficiency Changes What Content Needs to Do
Most teams assume buyers decide once they understand the offer. Buyers decide once they can verify it without doing extra work.
Decision efficiency is the verification cost.
It gets overlooked in most content, even though it shapes whether a buyer can move forward with confidence. If the content does not resolve the issues blocking progress, the decision slows down even when the offer itself is clear.
Comparative content helps because it reduces the work required to evaluate options. It clarifies tradeoffs, shows who a solution is for, and makes the choice easier to verify.
This breaks down into three parts:
- FLUQs: the unasked questions that block progress, including risk, fit, edge cases, switching cost, and internal pushback
- Decision Efficiency: the criteria that separate options in the category, plus the specific proof that makes positioning credible
- UVP: the specific outcome delivered for a specific buyer, with the tradeoff made explicit so the impact of the choice is clear
From there, the content has to connect outcomes to real offerings. Outcome-to-Offering (O2O) is the structure for doing that.
- Canonicalize offerings: use exact feature names and ban synonyms so retrieval does not fragment the concept across multiple terms
- Add “find it” locators: include explicit UI access paths so the chunk points to a verifiable workflow
- Build the O2O reference layer: map each buyer outcome to the canonical offering plus access path, then reuse the same insert pattern across documents
- Handle overlap with rules: define conditional logic for overlapping features and different personas so retrieval resolves to the right offering
Publish in a way that helps buyers verify the choice and helps AI systems retrieve, cite, and connect the right outcome to the right offering.
What to Measure and Build Next
AI answers change both the work and the proof. It’s not enough to publish broadly, rank a page, and point to traffic.
Brands need to shape what models retrieve and cite when buyers compare options, and they need reporting that shows whether that work is changing recommendation outcomes.
The priority is no longer just page visibility. You need decision visibility.
Brands need decision assets on their own site and on third-party surfaces that help models resolve fit, trade-offs, and proof. Those assets need to be clear enough to retrieve, specific enough to cite, and structured enough to support a recommendation.
It also changes how progress should be tracked. A useful reporting model does not stop at whether a brand appeared in a prompt. It tracks where the brand was placed when the prompt forced comparison, whether it was recommended or warned against, which citations supported that outcome, and how that behavior shifts across repeat runs and different AI surfaces.
That’s how brands stay visible when the prompt forced comparison and the answer happened before the click.




