Traditional SEO focuses on ranking pages. Many AI search experiences start by retrieving a source set (‘grounding’ is the emerging reference for this process) and generating an answer from it.
For bottom-of-funnel prompts that focus on the purchasing decision, retrieval-backed systems often favor sources that have already done the comparison work: category coverage, explicit trade-offs, and a structure that makes selection logic easy to reuse.
If your brand is not in that comparison-shaped source set, it’s easier for the model to exclude you or describe you in ways you don’t control (for example, AI hallucinations are often an inferred fact or detail the AI model didn’t have information on explicitly).
Off-domain comparison assets get pulled and cited when they fit what the system retrieves. Microsites are one way to publish them.
That’s the hypothesis we shared with our client, an enterprise firm in a highly competitive search environment where small visibility shifts translate into revenue.
The results of our experiment illustrated a lever that many SEOs ignore.
The Role of off-domain Comparison Assets in LLM Visibility
An off-domain comparison asset is a narrowly scoped, off-domain page built to answer high-intent selection prompts such as “best X for Y,” where the reader is trying to choose a solution.
You can create these through off-domain guest posts or microsites.
A microsite is one way to publish an off-domain comparison asset: a narrowly scoped page designed to help a buyer choose by comparing options side-by-side for a specific decision. It reflects FAQs, FLUQs (Friction-Inducing Latent Unasked Questions), and other BOFU content. And it performs better when the content structure aligns with the prompt’s intent classification.
It is not educational-based content.
In many AI search experiences, third-party comparison pages (brand-independent, affiliate-style, often targeting FLUQs) often appear in citations for comparative prompts and can influence framing.
Those pages shape what gets mentioned and how each option is described, so if you aren’t present in the formats the AI search system keeps citing, you often don’t make the list.
You’re not ranking for the prompt itself.
You’re trying to show up in the retrieved source set that the AI search system uses before it recommends anything. Those sources shape which brands it includes and how it describes them.
Off-domain comparison assets can be published in different formats. Microsites are one way to publish a comparison asset that fits what the AI search system retrieves and cites.
We ran a controlled test using microsites due to client goals and constraints.
Minimum Criteria for Off-Domain Comparison Assets
| Criterion | What qualifies | What does not qualify |
|---|---|---|
| Narrow scope | Built around a “best X for Y” comparison use case in a specific space, for a specific audience. | A broad explainer page, or a head term category page that is not built around a specific “best X for Y” selection question. |
| Category coverage | The asset includes a table that compares providers in the category for a specific audience and decision context, using columns that reflect the decider’s criteria. | A single brand page, or content that mentions alternatives in passing but does not compare providers side by side. |
| Repeatable comparison structure | The asset follows the repeating structure (for the particular intent): callout at the top, table, ranking, plus pros and cons. | A narrative-only page where the comparison logic is buried, or a page that never commits to a ranked view of options. |
| Tradeoffs made explicit | The asset states pros and cons or equivalent tradeoffs. | A page that avoids tradeoffs, stays generic, or describes options without stating what each is good at and bad at. |
Deploying Microsites for a Competitive Enterprise Category
We built off-domain microsites that compare products or services in the client’s category, designed to match the comparison structure of prompts like ‘best X for Y’, the system retrieves and cites that align with (and vary by) the intent classification of the original prompt.
What we tested:
- When a microsite gets cited at least once in a prompt series, does the client’s average rank improve versus a series where no microsite is ever cited?
- When the microsite is cited, does the model mention the brand earlier, and does it help defend a top 1 or 2 spot in the ranked list?
- Is any observed difference statistically significant when comparing runs where the microsite is cited versus runs where it isn’t?
Each microsite had:
- A clear top recommendation with a short rationale.
- A comparison table above the scroll that covers the category set.
- A ranked list of providers with short descriptions, modeled on best of and review pages.
- Pros and cons per option to make tradeoffs explicit.
- Modular content sections (chunks), starting with frequently unasked questions.
How we measured movement:
We used XOFU prompt visibility data to track citations, mentions, and rank position across prompt series.
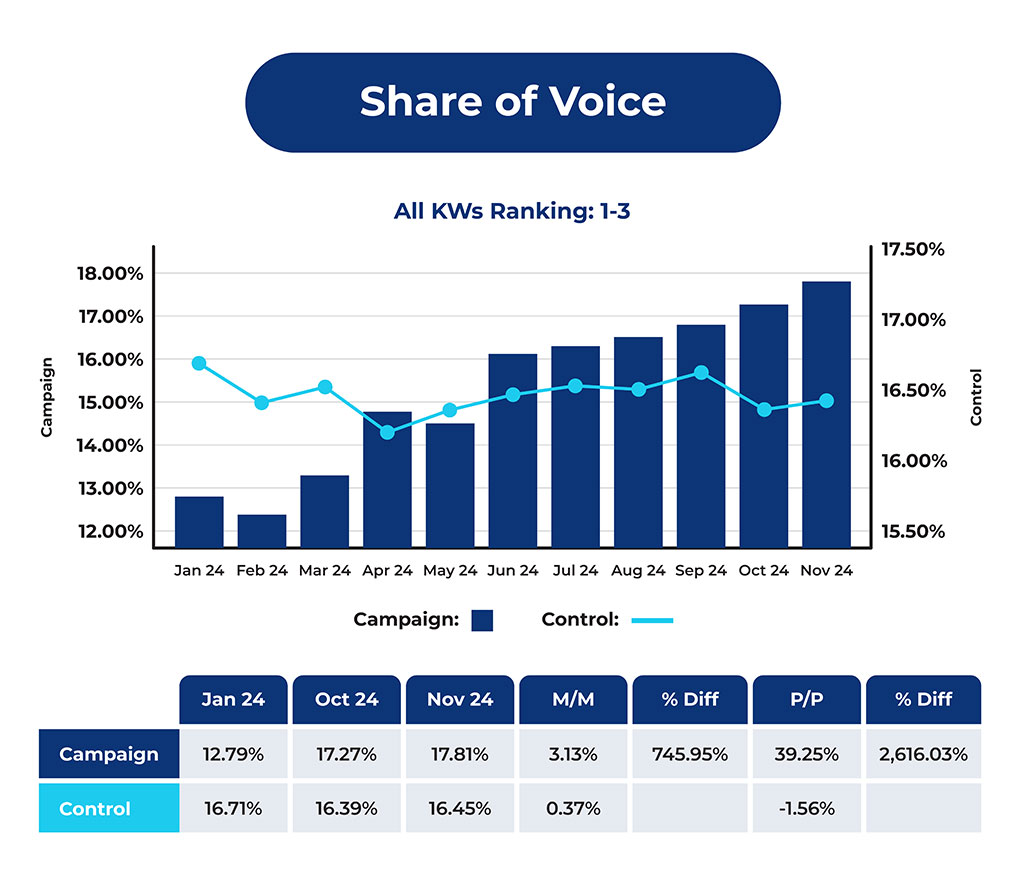
Here is the data we analyzed:

Results:
- The client sat between positions #1 and #2, and the instances where the microsites were cited notably outperformed the instances where they were not cited.
- The movement was small, but statistically significant in the comparison between the two datasets.
In practice, inclusion comes down to whether the page matches the comparison structure the model expects, carries sufficient trust, and has distribution signals that pull it into the citation set.
Models Build Context Before They Answer Queries
For many comparative questions, models do not start by choosing brands.
They start by building context (a process more frequently referred to as ‘grounding’). In retrieval-backed AI search, the system may expand the query, retrieve pages, and then synthesize the answer. The early inputs shape what gets mentioned, how each option is described, and which brands never enter the list.
This is why your best landing page often does not show up early.
The model is not at the brand level yet. Depending on the intent classification derived from the prompt, it is looking for sources that already did the comparison work: category coverage, clear differences, explicit tradeoffs, and a structure that makes the decision easy to follow.
You can see this pattern fast.
Run your target prompts and review the cited sources. Then, ignore your site and direct competitors. What remains is the third-party slice to study for gaps and opportunities.
If you are missing from that backbone, you have two choices:
- Get your brand included in the third-party comparison pages the system currently cites.
- Publish off-domain comparison assets that match the same structure the system cites.
Warning: Structure for Humans First
There’s an extreme version of chunking that appears to game AI models.
Teams publish pages made of dozens of standalone 200-word blocks where each block is its own topic, the page is not cohesive, and nobody would read it by choice.
That content is not built for an end user or conversion.
That is not what we are describing.
Chunking only works when it supports decision-making. The safer principle is user first structure: put information in the right order, make tradeoffs explicit, and help a human make a better decision—faster.
If the off-domain comparison asset exists only to create a path of least resistance for a model while ignoring human utility, you’re telling the wrong story and underoptimizing for your buyer.
Launching Your Off-Domain Comparison Pilot
There are two ways to run this: do it yourself with the checklist below, or have us run the pilot and share the findings.
Note: Building and scaling this internally takes time and approvals. We have systems and tooling to run this for you at scale and in a fraction of the time.
If you want to run a pilot internally, do this:
- Pick 10 to 20 high-intent “best X for Y” prompts that your buyers use. (Use XOFU to find and track BOFU prompts.)
- Run the prompt set: export citations, brand mentions, and list position.
- Remove your site and direct competitors from the citation list. Review what remains to identify where third-party support is missing or weak, and where you could add it.
- Scan that remaining set and note the repeating structure: top pick callout, table above the scroll, ranked list, pros and cons, and friction-inducing latent unasked questions.
- Build one off-domain comparison asset (guest post or microsite) that matches that structure for one of the prompt clusters.
- Re-run the same prompt set in your LLM tracking tool after the asset is live.
- Track three movements: whether the asset enters the cited set, whether your mention happens earlier, and whether the list position moves.
Review results and decide whether the pattern holds in your category.





