Citation Labs worked with Eric Van Buskirk and Clickstream Solutions to study how buyers build shortlists for major purchases in AI Mode and Google’s standard Search experience.
The study tracked observed behavior during research into high-value purchases, using simulated buying tasks in which participants helped narrow options for someone making a major purchase.
(Full methodology and study details are covered in the full report.)
In AI Mode, buyers often accepted or refined the shortlist presented to them rather than building one through broader comparison. That means you can be excluded before buyers start comparing options.
Xofu’s visibility data pointed in the same direction.
Across the same purchase categories, the brands participants shortlisted were often the same brands Xofu tracked as most visible in AI recommendation environments.
AI Shapes the Shortlist Before Comparison Begins
The behavioral study shows that AI Mode often turned shortlisting into acceptance.
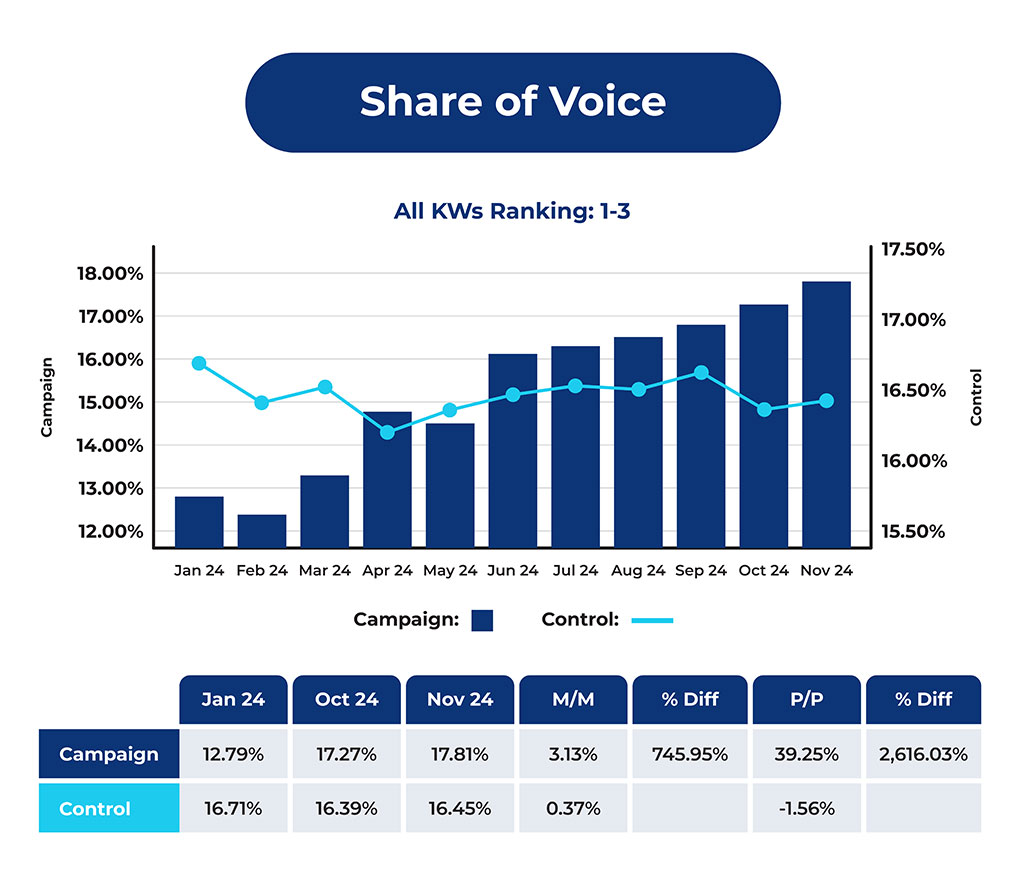
In 74% of AI Mode tasks, the shortlist came straight from the AI output. In 64% of tasks, participants clicked nothing before naming finalists.
In standard Search, the pattern was different. Users clicked through results, compared sources, and built the shortlist more independently.
Xofu gave us a way to see whether the brands people chose were also the brands most visible in AI recommendation environments.
We compared participant brand choice with Xofu visibility rankings across the same four purchase categories: televisions, washers and dryers, laptops, and driver insurance. And we used rank-biased overlap (RBO) to measure how closely Xofu’s visibility rankings aligned with the brands participants shortlisted.
Higher scores indicate stronger alignment.
The strongest alignment was observed for televisions and washers and dryers, with RBO scores of 0.812 and 0.853, respectively. The laptop task also showed clear alignment at 0.754.
For brands, this suggests Xofu’s visibility rankings can align directionally with shortlist outcomes in some categories.
It also suggests you can track rank in AI.
Across those categories, the brands participants chose most often were usually the ones Xofu tracked as most visible in the AI recommendation environment.
Driver insurance was the exception with an RBO score of 0.236.
In this category, participants’ choices didn’t closely align with Xofu’s visibility rankings. Two factors likely drove that mismatch:
- The comparison set was less clean: participant choices included regional insurers and comparison-style providers that didn’t always appear in Xofu’s ranked set.
- Insurance buyers needed quote-level pricing and profile-specific details that AI couldn’t reliably surface.
Instead, AI outputs often provided percentage discounts or broad estimates. Participants treated that formatting as decision support.
In this category, visibility appeared to be a weaker proxy for shortlist outcomes due to category fragmentation, brand familiarity, and perceived price specificity that shape choices more heavily.
For brands in categories with opaque or conditional buying details, appearing in the answer isn’t enough. The supporting information has to make the choice easier to evaluate.
What AI Visibility Means for Shortlist Inclusion
Comparing Xofu visibility data with the behavioral study shows you can track AI visibility in a directionally useful way.
In categories where buyers can compare options with clear, concrete details, the brands most visible in AI recommendation environments were often the same ones participants shortlisted.
However, that doesn’t mean visibility determines the decision. Instead, visibility can act as an early signal of whether a brand is likely to enter consideration.
The exception shows the limit of visibility as a proxy for shortlist outcomes in some categories.
In messier categories, visibility and shortlist outcomes can diverge because choice depends more heavily on factors AI may not surface cleanly.
This is an opportunity for brands in opaque categories to share the details buyers need to shortlist them, especially when competitors leave those details unclear.
Search Principles Still Apply in AI Environments
AI changes how buyers form shortlists, but it hasn’t changed the underlying visibility problem.
In standard search, buyers didn’t click to page 7 or 82 to find an option. They focus on the top-ranking pages. AI systems work similarly, pulling citations from the query fanout. They work from a narrower set of sources, pages, and descriptors, then compress those inputs into a much smaller recommendation layer.
It’s the path of least resistance for machines and humans.
A brand can’t rely on broad rankings, generic category relevance, or scattered mentions to stay visible. It needs to appear in the sources that inform the answer, on the pages that support the claim, and in the language the system can use when describing the brand.
If that supporting layer is thin, vague, or absent, the brand has fewer chances to enter consideration at all.
The underlying work is similar to traditional SEO in some ways. But the inputs need improvement. Brands need enough citation coverage to enter the cited set, recurring descriptors that support how they should be framed, and pages that make those claims easy to retrieve and reuse.
That shifts what you measure.
Teams need to know which prompts trigger recommendation lists, which pages and domains appear in those outputs, which competitors are cited instead, and which descriptors recur in the answer set.
General visibility reporting is too broad for that job. The useful unit of analysis is now the prompt, the page, the source, and the citation pattern behind the result.
More Visibility Doesn’t Guarantee More Customers
These findings reflect observed shortlist behavior in a simulated buying task, in which participants helped someone else narrow down options rather than making the purchase themselves.
Visibility can increase the odds that a brand enters consideration, but it doesn’t guarantee selection.
In AI Mode, the AI’s framing drove decisions in 48% of tasks, while brand recognition shaped many of the rest.
Being ranked first strongly predicted selection, but even rank overrides usually remained within the AI-adapted shortlist. A brand can appear often and still lose if the supporting information is weak, confusing, or easy to dismiss.
Teams can’t stop at visibility.
They need to understand not only whether the brand appears, but how it is described, which sources shape that description, and whether the pricing, proof, and language make the brand easier to trust once it enters the shortlist.
Citation Optimization: How Brands Earn Shortlist Inclusion
Citation optimization is the process of increasing how often and how well a brand gets recommended in AI answers by improving the pages and third-party sources that those systems use to justify those recommendations.
In many cases, that means improving the sources surfaced through query fan-outs (even when those fan-outs aren’t visible or explicitly cited in the final answer).
Shortlist visibility depends on whether there are enough clear resources that validate the use of your product or service in the answer to the question.
Optimizing these citations influences whether AI answers recommend, list, omit, or warn people against your brand.
| Step | What To Look At | What To Do |
|---|---|---|
| 1. Build the prompt set | The BOFU prompts buyers use to shortlist services and products | Group prompts by comparison, feature, use case, and vendor selection |
| 2. Measure the outcome | Whether the brand is recommended, listed, omitted, or warned against | Review the answer set and log the outcome by prompt |
| 3. Inspect the evidence | The sources and pages AI uses to support that outcome | Identify the cited pages, third-party sources, and competitor support behind the result |
| 4. Improve the inputs | The pages and sources shaping shortlist answers | Add detailed comparisons, decision criteria, and data to the pages AI cites |
| 5. Recheck the same prompts | Whether on-site and/or off-site work improved visibility | Rerun the prompt set and track changes in visibility, citations, and competitive position |
Then, you need to track performance.
Instead of focusing on brand-awareness-type prompts (TOFU) and tracking keywords, you target bottom of funnel prompts (BOFU) around comparison and choice and persona and context—the kinds of queries that force the model to list options and cite solutions that could work (or ones to avoid).
You track which competitors appear in these prompts, which pages and domains get cited, and which descriptors recur around those brands.
Xofu helps teams run and rerun the same decision-stage prompts over time so they can see where their brand appears, which competitors show up, and how citation patterns change.
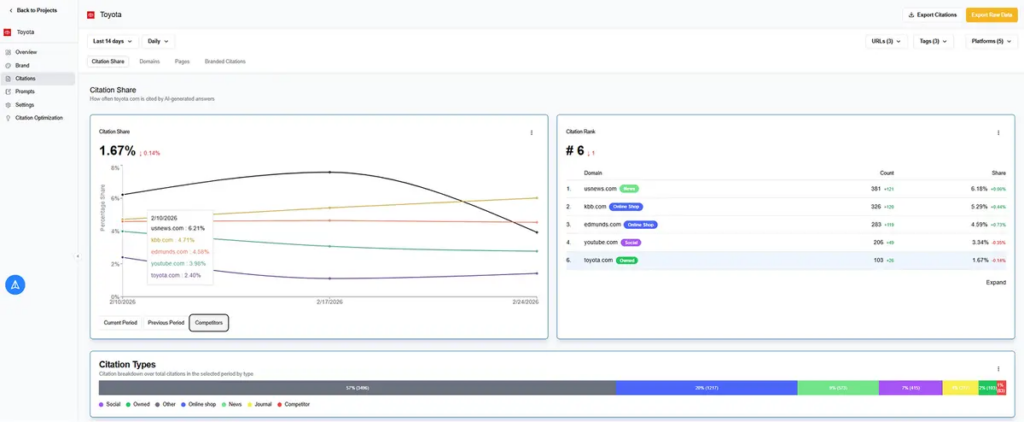
From there, improve the pages and sources tied to those prompts with clearer comparisons, sharper decision criteria, stronger evidence, and language AI systems can retrieve and reuse.
These assets can be on-site or off-site.
Either way, remember that AI shortlist environments put more pressure on the supporting layer behind the answer. Pages need enough detail to help a model justify their inclusion, accurately frame the brand, and support the recommendation with specifics.
Teams that want shortlist inclusion need to know which prompts shape consideration, which sources feed those answers, how competitors keep adding to the citation set, and what information their brand provides to AI systems to work with.