The meteor has hit web publishing.
Head on.
We’re experiencing the shockwaves, and they’re not slowing down. They’re ripping through content teams right now.
Most content isn’t dead because it’s bad. It’s dead because it’s useless to AI. It’s too long, too vague, and not structured for synthesis or reuse.
It’s built for pageviews instead of parsing.
LLMs don’t need your blog post. They don’t care about your narrative. They want to extract something fast, efficiently, and economically.
If your content is too general or too new and localized, it gets ignored. Doesn’t matter how well-written it is or how high it ranks.
It’s invisible.
You must create content that can be reused, synthesized, cited or invoked.
Naturally, we turn to Google for advice.
But that’s a whole different story…
Search Isn’t in Charge Anymore
Google summoned me and a few other SEOs as part of a strange delegation to the court of Google, post-keynote on Day 1 of I/O.
This delegation of SEOs sought recourse and guidance in our traffic apocalypse. Google held this meeting within an hour of its AI Mode demonstration (which promises to eat the rest of the traffic that AIOs haven’t touched yet).
One thing was clear during my visit: Search isn’t in charge anymore. Gemini is.
What blew my mind is that Google’s own search engineers (6000+ developers) didn’t even know AI overviews were becoming the default.
That’s how existential this is.
It broke my fucking brain.
Google’s making changes their own team doesn’t even know about. It’s breakneck survival right now. They’re reacting to how quickly ChatGPT got out in front of everyone. And now they’ve got to show the market they still matter.
But while all that’s happening, they’re telling us to keep on publishing.
Publish content. Make it high quality. Make it useful. But don’t expect attribution. Don’t expect traffic. Don’t expect to know if you got cited, or if someone used your work to feed a model.
You’re supposed to just do it.
You won’t receive a ping. There’s no loop. There’s an invisible prompt stack behind every overview, and you don’t get to see it.
You’re working in the dark, and no one’s going to tell you what to do next.
Why Most Content Gets Ignored by AI
Right now, marketers aren’t structuring content for synthesis or reuse. We’re not codifying, creating objects, or disambiguating.
We’re publishing long pages with rambling paragraphs and no signal or relevance to the user’s needs for the LLM to cite it.
The model’s asking:
- Who’s the expert?
- What’s the assertion?
- Where’s the proof?
And we’re not giving it an answer. So we don’t get picked up or cited. (Maybe we get hallucinated, but that’s not the same.)
Most of today’s content is just dictionary work: bland, redundant, and easily replaced. But there are 10,000 other dictionaries out there. And none of them are getting cited, either.
We’re still building for engagement and optimizing the old system. I get it. SEOs are clinging to what worked. It’s hard to change. But that’s the problem. The web’s basically gone. That’s why we’re getting ghosted.
The intent is still locked in 2018.
That’s not going to work for LLMs.

You’re No Longer Writing for People
Content that gets reused is content that survives. That means net-new information—designed for LLMs, not just human readers.
If you’re not actively disrupting your own assumptions, your content won’t show up. It needs to be radically original.
Think Darwin landing on the Galapagos.
You’re not building SEO content. You’re mapping unknown terrain, tearing down your own beliefs to surface something new.
And even if you nail it, even if you publish something brilliant, it might vanish. No attribution. No loop.
Just gone.
This is the shift most teams still haven’t internalized: You’re not just writing for people. You’re writing for the model.
However, there are ways to engineer your placement and increase your chances of success.
Citation Engineering Makes Content Reusable by LLMs
We’re already in a GPT-to-GPT publishing loop, where language models reuse what other language models wrote. If your content isn’t structured for that kind of reuse, it gets skipped.
How do you structure it?
Your work needs the best chance of being cited (on-site and off-site), regardless of whether a human writes it or not. AI tools only care about aligning answers with hyper-personalized user requests.
To do that, you need Citation Engineering.
Citation Engineering increases your content footprint across a digital space with a combination of net-new, evolving content and numerous mentions. This gives your assets the best chance of survival and gives your business the best chance of being cited in the answer.
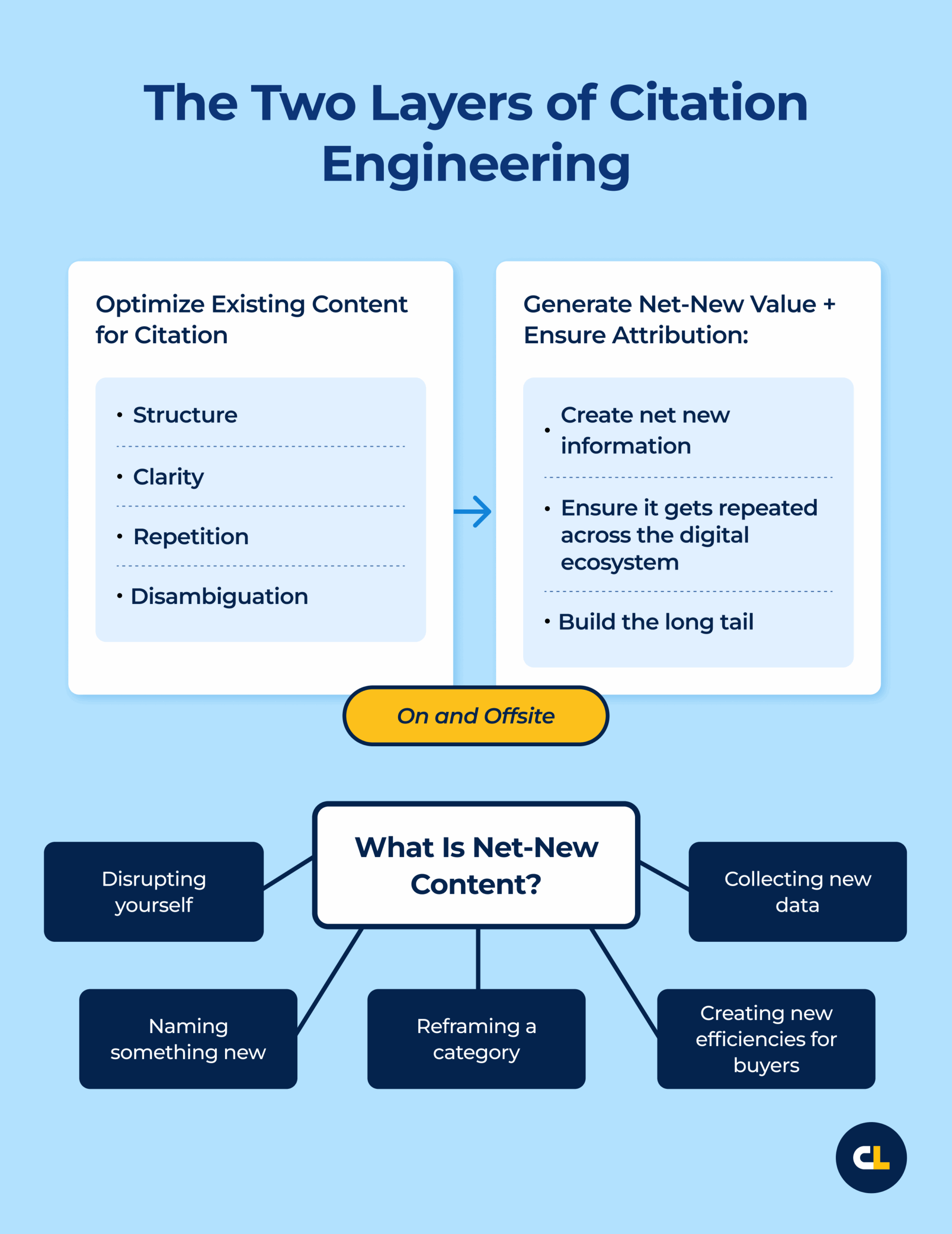
There are two layers to Citation Engineering:
- Optimize Existing Content for Citation: Do your utmost on and off-site to ensure that what exists now is as citable as possible. That means structure. Clarity. Repetition. Disambiguation.
- Generate Net-New Value + Ensure Attribution: Create net new information. Then, ensure it gets repeated across the digital ecosystem to build the long tail.
What is net-new?
- Disrupting yourself
- Naming something new
- Reframing a category
- Collecting new data
- Creating new efficiencies for buyers
Remember: Publishing new insights isn’t enough. If you don’t reinforce it (on and off your sit) it gets scraped, stripped, and reused without your name.
You need to build new schemas.
Where to Go to Build Net-New Schemas?
The same structure (same schema) needs to show up across pages, and across domains. That’s how you reinforce the signal and survive the pattern-matching.
The schema can’t just live on your site. It needs reinforcement across domains: your own and others. Could be as citations. Could be brand mentions. Could be other ways.
That’s how you stay visible.
Backlinks still matter, just not because they pass PageRank. They’re how LLMs detect consensus and reinforce schema across domains.
Citation Engineering just makes that intent explicit.
Some teams are also starting to test for reuse patterns directly, examining where their content might already be appearing in model outputs, even if they’re not being credited.
At Citation Labs, we’re helping clients identify this schema and build for it to increase LLM mentions.
How Xofu Guides Content Creation for Reuse
Want survivability and visibility? It starts with Citation Engineering. You can’t write for search anymore. You have to write for prompts.
Try this prompt.
It’ll help you understand the types of prompts your buyers use. And you can review those results and keep running the prompt to get more.
Or, you can test this out with Xofu.
You drop in a real-world prompt (something a buyer or journalist might actually type) and it runs your content against it. You’ll see where you’re aligned, and where you’re not.
Then you’ve got options:
- Refactor what you’ve got
- Generate a new object
- Or prompt for disambiguation
This isn’t a grading system. There’s no score.
Just the next move.
And this isn’t a one-off fix. If your team isn’t actively updating an internal best practices index, you’re falling behind. Schema isn’t static, and neither is survivability.
Who’s Getting Erased (And What to Do About It)
Citation engineering is for SEOs, corpus owners, and AI-forward publishers, anyone watching traffic vanish and realizing: we’re disappearing into the universe-sized LLM black box.
It’s for people building content they actually want reused.
That means prompt-aligned. Token-efficient. Built for disambiguation, not engagement.
But even new thinking isn’t enough. If your schema doesn’t get reinforced, it dies. The model skips it or strips it for parts.
That’s the real risk. You think you published something original. But if it doesn’t show up in the next prompt cycle, it’s gone.
And still, SEOs cling to SEO.
It’s jaw-dropping.