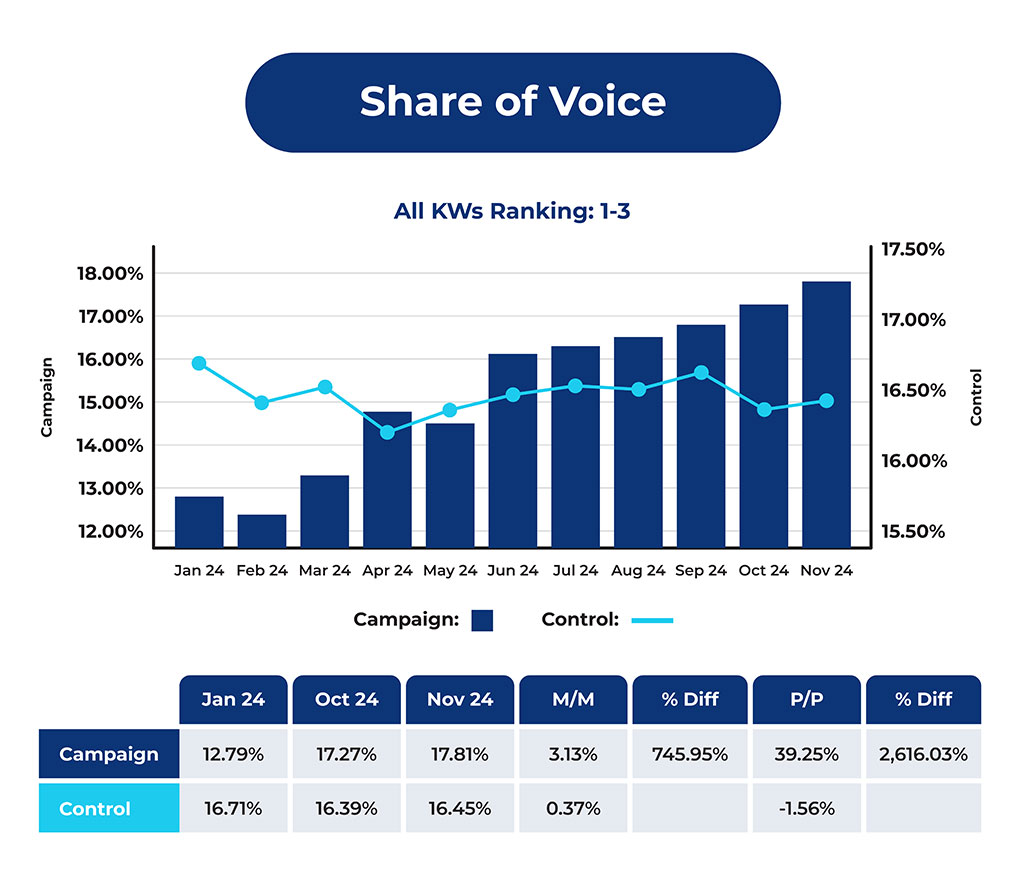
Designing Tracking-Ready Decision-Stage Queries for Visibility Analysis
01 — Purpose and System Context
The BOFU Prompt Authoring Guide defines how to construct decision-stage prompts that generate trackable, analyzable, and ethically comparative visibility data.
These prompts are not marketing queries.
They are instrumented probes — designed to measure what an AI system knows, retrieves, and reasons about when a user reaches the point of decision.
Within the XOFU Visibility Engine, each BOFU prompt acts as a structured visibility test against a corpus, a model, and a marketplace.
Its role is to surface:
- What information is retrievable at the bottom of the funnel,
- Whether that information is sufficient for an informed choice, and
- How a brand or offer compares to credible alternatives.
02 — Core Definition: “Tracking-Worthy Prompt”
A tracking-worthy prompt is one that:
- Produces structured, multi-entity outputs (multiple brands, products, or options).
- Maps cleanly to a URL or offering within XOFU.com’s visibility tracking schema.
- Embeds the intent, category, and constraint signals necessary for model interpretability.
- Is written in natural, decision-stage language that an LLM will recognize as a comparison or choice query.
In practical terms: A tracking-worthy prompt isn’t just answerable — it’s auditable.
03 — Decision-Stage Query Architecture
At the bottom of the funnel, the user’s cognitive frame shifts from discovery to justification. Language reflects that shift.
Decision-stage prompts must therefore encode three semantic anchors:
| Anchor | Function | Example |
|---|---|---|
| Intent Verb | Establishes decision context | “choose,” “compare,” “decide,” “select,” “evaluate” |
| Category Noun | Activates retrieval scope | “expense automation platforms,” “CRM tools,” “AI writing assistants” |
| Constraint / Modifier | Narrows to evaluative dimension | “for small teams,” “under $100/month,” “that integrate with Slack” |
Together, these anchors form a query architecture that can be parsed, logged, and measured within XOFU’s system schema.
04 — Construction Principles for BOFU Prompts
| Principle | Description | Why It Matters for Tracking |
|---|---|---|
| Plural Framing | Always reference a set of options. | Enables multi-entity extraction and mention ranking. |
| Comparative Operators | Use contrastive words — “best,” “better,” “vs,” “trade-off,” “compare.” | Triggers model reasoning chains that enumerate alternatives. |
| Constraint Diversity | Embed 3–5 constraint types: price, reliability, integration, support, compliance. | Creates multidimensional tracking clusters per offer. |
| Neutral Tone | Avoid brand-leading or promotional language. | Maintains data integrity — AI responses reflect true citation weight. |
| Natural Syntax | Write as a peer-level question. | Ensures LLMs treat the query as an authentic user intent. |
Tracking depends on linguistic neutrality: a biased or overly branded prompt invalidates measurement by distorting model recall.
05 — BOFU Prompt Archetypes
Each archetype represents a distinct buyer cognition pattern and corresponding LLM retrieval behavior.
Used collectively, they form a complete diagnostic of decision-stage visibility.
| Archetype | Cognitive Intent | Prompt Logic | Example |
|---|---|---|---|
| Best-for-Me | “Which option aligns best with my specific constraints?” | Best + Constraint | “What’s the best payroll platform for global teams under 100 employees?” |
| Worth-It | “Is this category worth paying for vs free alternatives?” | Value Comparison | “Is paid expense software worth it compared to spreadsheets?” |
| Switch-Cost | “What happens if I migrate from X to Y?” | Contrastive Change | “What are the downsides of switching from QuickBooks to Ramp?” |
| Specialist-Fit | “Which tool fits my role, industry, or tech stack?” | Persona / Context Match | “Which CRM works best for small B2B agencies?” |
| Long-Term-Fit | “Which solution proves most stable or supported over time?” | Reliability & Continuity | “Which automation tools are most reliable for scaling operations long-term?” |
Each archetype tests a different retrieval corridor within the model’s semantic space.
Together, they yield a balanced dataset for measuring both brand presence and reasoning completeness.
06 — Metadata & Schema Alignment (XOFU.com Integration)
Every prompt must bind to a unique sales-page or product URL. To remain machine-traceable, maintain consistent metadata fields across the corpus.
Core Tracking Fields:
- Prompt_text: The natural language question.
- Intent_verb: The main decision verb (e.g., “compare,” “choose”).
- Category: The domain or product group.
- Constraint: The condition, modifier, or use case.
- Persona: Who is asking the question.
- Stage: “BOFU.”
- Target_url: The sales or offer page under analysis.
Each prompt-URL pair forms a single visibility test unit in the XOFU analytics pipeline.
Best Practices for Schema Hygiene:
- Keep field labels lowercase and deterministic (no variants of “compare vs comparing”).
- Use short, plain nouns for category values.
- Record one persona per prompt for clarity (e.g., “finance lead,” “operations director”).
Avoid stacking multiple constraints in one prompt; vary them across the suite.
07 — Suite Design for Statistical Stability
A meaningful dataset requires coverage breadth and lexical variation without redundancy.
Follow this rule of thumb:
- 15–20 prompts per target URL
- At least 3 archetypes represented
- Each archetype repeated under 3–5 distinct constraints
- Prompt phrasing diversified via natural synonyms, not structure rewrites
The goal is not quantity but representational coverage — enough distinct linguistic surfaces for the model to expose consistent entity behavior.
08 — Developer Guidance: Implementation Considerations
Prompt Generation Logic:
- Use deterministic sampling (low temperature) for prompt seeding to ensure test reproducibility.
- Introduce controlled lexical variation (e.g., “tools,” “platforms,” “solutions”) to test model sensitivity.
- Avoid structural duplication; model evaluation frameworks should deduplicate by intent, not token string.
Logging & Evaluation:
- Log all prompt–response pairs with timestamps and model identifiers.
- Normalize outputs into a consistent schema (entity, mention position, context sentiment).
- Ensure each test run can be replayed against future model versions for longitudinal comparison.
Model Environment Controls:
- Fix temperature between 0.1–0.3 for retrieval consistency.
- Use the same system instruction or wrapper context for all prompts within a batch.
- Record model build/version ID in metadata.
Consistency is what makes tracking possible. Entropy can be valuable — but only when intentional and logged.
09 — Practical Prompt Composition Checklist
Before deployment, confirm each prompt:
- Uses plural, comparative phrasing.
- Includes a clear intent verb and constraint.
- Omits brand bias or promotional tone.
- Maps to exactly one target URL.
- Aligns to an archetype pattern.
- Can be re-run across LLMs without ambiguity.
If all six checks are true, the prompt is tracking-ready.
10 — Theoretical Addendum: Why This Works
LLMs rank entities within answer generation not by keyword frequency but by semantic salience under intent alignment, which means the model prioritizes entities that best fulfill the query’s underlying purpose, not those that simply appear most often
By structuring prompts around explicit comparative logic, we cause the model to:
- Enumerate peer entities (creating measurable mention networks).
- Expose reasoning depth (revealing whether decision-stage content is adequate).
- Generate retrievable fragments (which can be parsed and logged with high fidelity).
This transforms prompt writing from an art into a controlled experimental protocol. BOFU prompts are not messages. They are measurement devices.
11 — Outcome
Implementing this guide ensures that every decision-stage prompt authored within XOFU.com is:
- Structured for retrieval,
- Comparable across models, and
- Directly mappable to web assets and brand entities.
The result is a consistent, auditable, and evolution-ready corpus of visibility data — capable of informing both strategic positioning and AI-era content engineering.
Appendix:
23 Characteristics of Tracking-Worthy BOFU Prompts
(The prompts that generate measurable, decision-stage visibility data)
Structural Characteristics
- Plural and Comparative:
– Use plural framing (“which tools,” “what platforms,” “how do X and Y compare”).
– Forces the LLM to enumerate multiple options → measurable visibility network. - Decision-Stage Intent:
– Built around verbs that imply choice or evaluation: compare, choose, decide, select, evaluate.
– Signals to the model that reasoning, not definition, is required. - Explicit Category Anchor:
– Clear product or service category noun (“CRM platforms,” “expense automation tools”).
– Keeps retrieval within a bounded semantic space. - Constraint-Driven Context:
– Adds a specific qualifier: budget, size, industry, integration, reliability, support, compliance.
– Enables multi-dimensional testing (e.g., “Which payroll platforms are best for startups under 50 employees?”). - Neutral and Unbranded:
– Avoids leading language (“the best,” “top-rated,” “why [Brand] is superior”).
– Ensures unbiased citation and authentic model reasoning. - Syntactically Natural:
– Reads like a genuine human query: conversational, specific, and plausible.
– Triggers natural retrieval pathways in LLMs.
Semantic & Cognitive Characteristics
- Decision-Framed, Not Informational:
– Reflects late-funnel cognition: “I’m ready to choose,” not “I want to learn.”
– Mimics the buyer’s mental comparison step. - Contrastive Reasoning Trigger:
– Uses language that demands evaluation (“better,” “worth it,” “trade-off,” “difference between”).
– Provokes side-by-side comparison → easier to measure entity weighting. - Multi-Entity Retrievability:
– The model can’t answer without mentioning multiple brands or tools.
– This property makes the prompt trackable (visibility data = mention + order). - Outcome-Oriented:
– Focuses on end benefit or goal (“for remote teams,” “to reduce errors,” “for scalability”).
– Anchors reasoning around user success conditions. - Cognitively Recognizable Archetype:
– Aligns with one of the five BOFU archetypes:- Best-for-Me (fit)
- Worth-It (value)
- Switch-Cost (transition risk)
- Specialist-Fit (persona alignment)
- Long-Term-Fit (durability)
Operational & Tracking Characteristics
- Schema-Compatible:
– Cleanly maps to XOFU tracking fields (prompt_text, intent_verb, category, constraint, persona, stage, target_url).
– Machine-interpretable → easy to store, query, and analyze. - Single-Target Mapping:
– Each prompt links to exactly one URL or offer page.
– Prevents cross-contamination in tracking data. - Model-Reproducible:
– Stable under low-temperature settings (T = 0.1–0.3).
– Produces consistent entity lists across runs → reliable longitudinal data. - Diverse Yet Deduplicated:
– Variations across constraints and archetypes, not phrasing redundancy.
– Maximizes coverage without inflating dataset size. - Prompt-to-Output Measurability:
– Generates extractable signals: entity mentions, rank order, sentiment, reasoning depth.
– Each output can be parsed, scored, and logged. - Cross-Model Portability:
– Works in multiple LLMs (Gemini, GPT-4 Turbo, Claude, Perplexity).
– Enables visibility benchmarking across ecosystems. - Short, Specific, and Singular:
– Each prompt tests one discrete scenario.
– Avoids compounding multiple intents in a single query. - Constraint Variety Coverage:
– Includes price, reliability, integration, support, and compliance angles.
– Ensures well-distributed tracking data for analytics dashboards. - Temporal and Context Independence:
– Can be re-run quarterly without context drift or ambiguity.
– Supports longitudinal trend analysis.
Optional (For Advanced Tracking Teams)
- Metadata-Tagged at Source:
– Each prompt logged with timestamp, model ID, and analyst tag.
– Enables auditability and repeat testing. - Archetype-Constraint Matrix Coverage:
– Every test suite spans at least 3 archetypes × 3 constraints = 9 prompts minimum.
– Scales up to 5 × 4 (20 prompts) for full diagnostics. - Ethical & Fairness Ready:
– Designed to reveal—not manipulate—LLM bias.
– Prompts ask for comparisons, not validations, to preserve interpretive integrity.
Summary
A tracking-worthy BOFU prompt is:
Plural, comparative, constraint-anchored, neutral, decision-framed, and schema-mapped — written so that an LLM must reason across multiple options and produce measurable, repeatable visibility data.